目录
- 永远的 Hello World
- 添加依赖
- 消息生产者
- 消息消费者
- Work Queues
- 消息确认
- 自动应答
- 消息手动应答
- 批量应答
- 消息的自动重新入队
- 公平调度
- 预取值(prefetchCount)
- 消息持久化
- 队列持久化
- 消息持久化
- 附录
永远的 Hello World
🎯通过本小节快速掌握如何通过 Java API 进行 RabbitMQ 的操作
添加依赖
pom.xml1
2
3
4
5
6
7
8
9
10
11
12
13
|
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.8.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
|
消息生产者
消息的生产者主要进行队列的声明,以及向队列中放入需要被消费的消息
Producer.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| public class Producer {
private final static String QUEUE*NAME = "hello";
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
String ip = "192.168.117.128";
String username = "admin";
factory.setHost(ip);
factory.setUsername(username);
String password = "123456";
factory.setPassword(password);
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
/\*\*
* 生成一个队列
_ 1.队列名称
_ 2.队列里面的消息是否持久化 默认消息存储在内存中
_ 3.该队列是否只供一个消费者进行消费 是否进行共享 true 可以多个消费者消费
_ 4.是否自动删除 最后一个消费者端开连接以后 该队列是否自动删除 true 自动删除
_ 5.其他参数
\*/
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
String message;
while (true) {
Scanner scanner = new Scanner(System.in);
message = scanner.next();
/\*\*
_ 发送一个消息
_ 1.发送到那个交换机
_ 2.路由的 key 是哪个
_ 3.其他的参数信息
_ 4.发送消息的消息体
\_/
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println("message send success");
TimeUnit.MILLISECONDS.sleep(100);
}
}
}
}
|
消息消费者
消息的消费者,主要定义两个回调函数(接收到消息的回调和消息接收失败的回调)
Consumer.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| public class Consumer {
private final static String QUEUE_NAME = "hello";
public static void main(String[] args) throws Exception {
ConnectionFactory connectionFactory = new ConnectionFactory();
String password = "123456";
String host = "192.168.117.128";
String username = "admin";
connectionFactory.setPassword(password);
connectionFactory.setHost(host);
connectionFactory.setUsername(username);
try (Connection connection = connectionFactory.newConnection();
Channel channel = connection.createChannel()) {
System.out.println("waiting from 2");
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody());
System.out.println(message);
System.out.println("received from c2");
};
CancelCallback cancelCallback = (consumerTag) -> {
System.out.println("message consume was interrupted");
};
while (true) {
TimeUnit.SECONDS.sleep(1);
/\*\*
_ 消费者消费消息
_ 1.消费哪个队列
_ 2.消费成功之后是否要自动应答 true 代表自动应答 false 手动应答
_ 3.消费者成功的回调
_ 4.消费未成功的回调
_/
channel.basicConsume(QUEUE_NAME, true, deliverCallback, cancelCallback);
}
}
}
}
|
Work Queues
😣通过 Hello World 能够向指定的队列发送和接收消息,但是存在以下问题:
假设有一些比较耗时的任务,按照之前的方式,要一直等前面的耗时任务完成了,才能接着处理后面耗时的任务,在如今的场景这样当然不合适,所以需要使用工作队列的方式进行消息的处理
❓什么是工作队列?
工作队列用来将耗时的任务分发给多个消费者(工作者),主要解决这样的问题:处理资源密集型任务,要等它完成了才能处理后续的任务。有了工作队列,就可以将具体的工作放到后面去做,将工作封装为一个消息,发送到队列中,一个工作进程就可以取出消息并完成工作。如果启动了多个工作进程,那么工作就可以在多个进程间共享。
📓工作队列(又称任务队列)的主要思想是避免立即执行资源密集型任务,而不得不等待它完成。可以安排任务之后再执行。通过将任务封装为消息并将其发送到队列。在后台运行的工作进程将弹出任务并最终执行作业。当有多个工作线程时,这些工作线程将一起处理这些任务
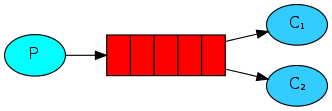
最终通过工作队列的方式做到消息在两个消费者间的轮询分发,做到下图的行为:
Consumer.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public class Consumer {
private final static String QUEUE_NAME = "hello";
static Channel channel;
static {
ConnectionFactory connectionFactory = new ConnectionFactory();
String password = "123456";
String host = "192.168.117.128";
String username = "admin";
connectionFactory.setPassword(password);
connectionFactory.setHost(host);
connectionFactory.setUsername(username);
try {
Connection connection = connectionFactory.newConnection();
channel = connection.createChannel();
} catch (IOException | TimeoutException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String receivedMessage = new String(delivery.getBody());
System.out.println("接收到消息:" + receivedMessage);
};
CancelCallback cancelCallback = (consumerTag) -> {
System.out.println(consumerTag + "消费者取消消费接口回调逻辑");
};
System.out.println("C1 消费者启动等待消费.................. ");
channel.basicConsume(QUEUE_NAME, true, deliverCallback, cancelCallback);
}
}
|
最终能够达到如下的效果:
消息确认
🤔如今已经完成的基本的操作,接下来考虑这样一件事:
消费者接收到消息后,需要花费较长的时间执行一个复杂任务,但是由于某种原因,消费者突然下线(宕机),当消费者再次上线工作时,上一次未处理完成的消息已经丢失。此时对于此消费者而言,不仅将丢失刚刚处理的消息,还将丢失所有已分配给该消费者但尚未处理的消息。出现以上事故,消息系统应当如何处理?
✨出现以上的原因,是由于默认配置下, RabbitMQ 一旦向消费者传递了一条消息后,会立即将该消息标记为删除(消息的自动应答)。此时如果消费者宕机了,由于消息队列已经将此消息删除,所以消费者将会丢失此前发送给消费者的所有消息,为了避免 RabbitMQ 删除消息,需要使用消息应答方式管理消息的生命周期
❓什么是消息应答
为了保证消息在发送过程中不丢失,rabbitmq 引入消息应答机制(消息确认),消费者发送确认消息,告诉 RabbitMQ 特定消息已被接收处理,RabbitMQ 可以删除将消息从队列中移除了
📓如果消费者在没有发送 ack 的情况下死亡(其通道关闭、连接关闭或 TCP 连接丢失),RabbitMQ 会将未完全处理的消息(没有被确认的消息)重新入队。如果有其他消费者同时在线,它会迅速将其重新交付给另一个消费者,这样就可以确保不会丢失任何消息。另一方面,对消费者确认有超时机制(默认为 30 分钟),有效的避免消费者花费较长时间执行某一个任务。
自动应答
✨消息发送后立即被认为传送成功。使用这种模式是在高吞吐量和数据传输安全性做权衡,因为如果消息在接收到之前,消费者那边出现连接或者 channel关闭,那么消息就丢失了,另一方面,如果消费者那边消息堆积严重,却并没有对传递的消息数量进行限制,这样有可能使得消费者由于接收太多消息,并且来不及处理的消息,导致消息的积压,最终使得程序 OOM
📓这种模式仅适用在消费者可以高效并以某种速率能够处理这些消息的情况下使用
消息手动应答
使用此代码,我们可以确保即使您在处理消息时使用 CTRL+C 结束工作人员进程,也不会丢失任何内容。因为进程结束后不久,所有未被确认的消息都将通过 RabbitMQ 重新分配
Worker.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
try {
doWork(message);
} finally {
System.out.println(" [x] Done");
/\*\*
_ 1. 消息标记 tag
_ 2. false 代表只应答接收到的那个传递消息,true 为应答所有传递过来的消息
\*/
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
};
boolean autoAck = false;
channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, consumerTag -> { });
|
🎶进行消息确认时,必须在接收交付的同一 channel 上发送确认,使用不同的 channel 进行确认将导致 chennel-level 的协议异常,详细信息查看官方文档
使用手动确认方式,但是在处理每一个消息后忘记增加 basicACK(),是一个非常常见且严重的错误,这种后果将导致客户端退出时,消息将被重新入队,最终会导致 RabbitMQ 消耗越来越多的内存,可以使用如下命令查看没有被确认的消息
1
| sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
|
✨手动应答的方法
Channel.basicAck (用于肯定确认),RabbitMQ 已知道该消息已经成功处理,可以将其丢弃了
Channel.basicNack 和 Channel.basicReject(用于否定确认),告知 RabbitMQ 需要接收那个消息
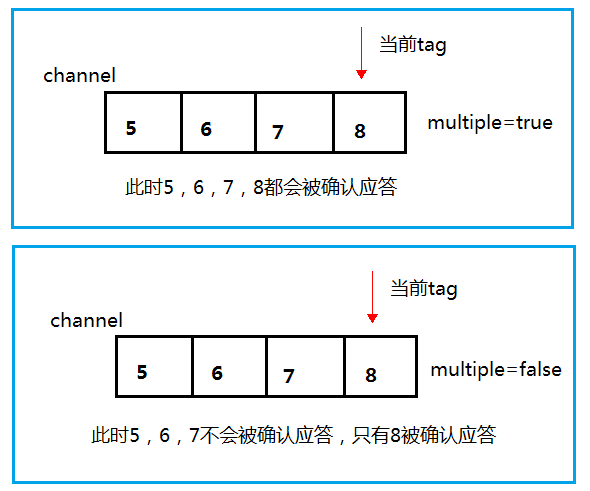
批量应答
通过手动的方式进行消息确认,可以做到消息的批量应答,减少网络通信的传输量,具体批量应答的工作方式如下图所示:
👴尽量不要启动批量应答,批量应答仍然可能造成消息的丢失
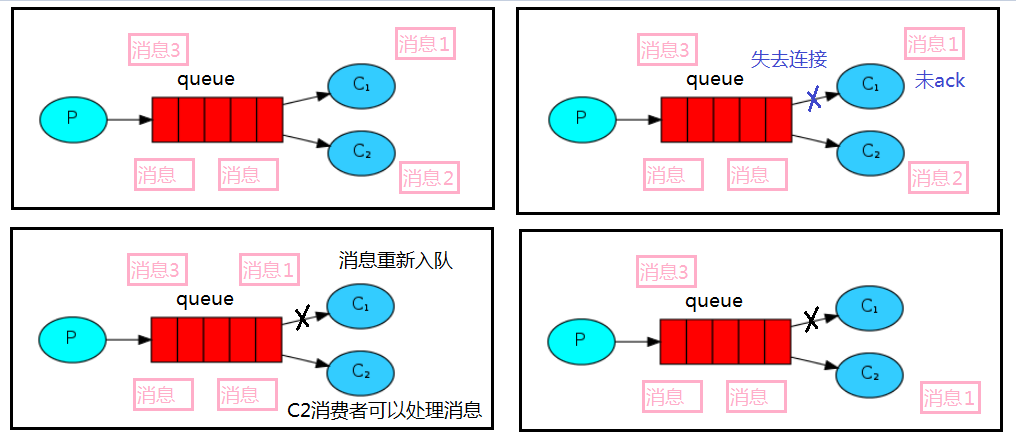
消息的自动重新入队
如果消费者由于某些原因失去连接(其通道已关闭,连接已关闭或 TCP 连接丢失),导致消息未发送 ACK 确认,RabbitMQ 将了解到消息未完全处理,并将对其重新入队。如果此时存在其他消费者空闲,RabbitMQ 会将消息重新分发给另一个消费者。这样,即使某个消费者偶尔宕机,也可以确保不会丢失任何消息
例如:首先发送两个消息 aa、bb 和 cc,随后发送消息 dd, 发出消息之后 C2 消费者突然宕机。按理说应该由 C2 来处理 dd 消息,但是由于 C2 处理时间较长,RabbitMQ 并未收到 C2 关于 dd 的确认时, C2 宕机了。RabbitMQ 一段时间后会将 dd 重新入队,然后分配给能处理消息的 C1 进行处理
公平调度
✨现在,您可能已经注意到,如此调度仍然不能完全按照我们想要的方式工作
例如:在有两个 worker 的情况下,当所有奇数消息都很重(执行时间长),偶数消息很轻时,一个 worker 会一直很忙,而另一个 worker 几乎不做任何工作。但是 RabbitMQ 对此一无所知,仍然会均匀地发送消息。如此并没有充分利用每一个工作者的能力,造成了资源的浪费
发生这种情况是因为:RabbitMQ 只是在消息进入队列时分派消息,它不会考虑消费者未确认消息的数量,只是盲目地将每条第 n 条消息分派给第 n 条消费者。所以最终极容易导致:消息堆积
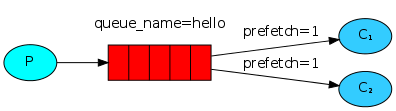
为了解决这个问题,我们可以使用带有 prefetchCount = 1 的 basicQos 方法。此方法告诉 RabbitMQ 一次不要给一个消费者多个消息,即:在处理并确认前一条消息之前,不要向消费者发送新消息。
1
2
| int prefetchCount = 1 ;
channel.basicQos(prefetchCount);
|
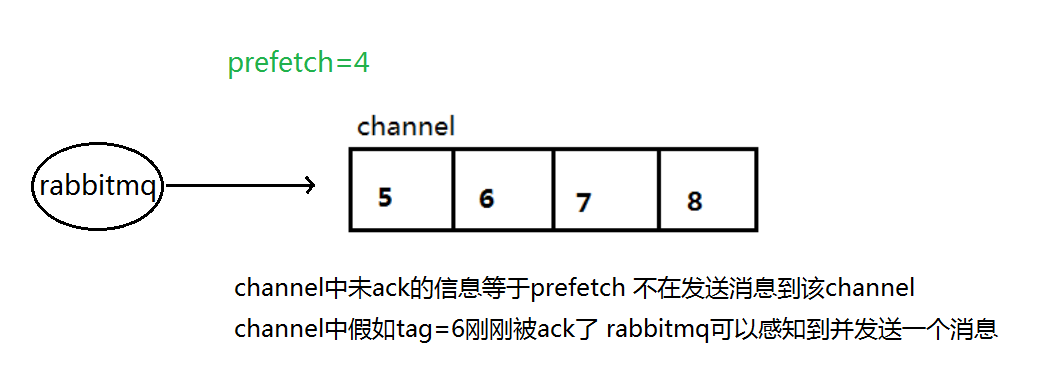
预取值(prefetchCount)
消费者一侧必然存在一个未确认的消息缓冲区,用来缓存接收到的消息,为了能够限制此缓冲区的大小,以避免缓冲区里面无限制的未确认消息问题。可以通过使用 basic.qos 方法设置预取计数值来完成的。该值定义通道上允许未确认消息的最大数量,一旦数量达到上限,RabbitMQ 将停止向该通道传递更多消息,只到此通道上有消息被消费完成了,MQ 才会继续向此通道传递消息
例如,假设在通道上有未确认的消息 5、 6、 7, 8,并且通道的预取计数设置为 4,此时 RabbitMQ 将不会在该通道上再传递任何消息,除非至少有一个未应答的消息被 ack。比方说 tag=6 这个消息刚刚被确认 ACK, RabbitMQ 将会感知到这个情况并再发送一条消息
消息应答和 QoS 预取值对用户吞吐量有重大影响。通常,增加预取值将提高向消费者传递消息的速度。应该小心使用具有无限预处理的自动确认模式或手动确认模式,消费者消费了大量的消息如果没有确认的话,会导致消费者连接节点的内存消耗变大。
找到合适的预取值是一个反复试验的过程,不同的负载该值取值也不同 100 到 300 范围内的值通常可提供最佳的吞吐量,并且不会给消费者带来太大的风险。预取值为 1 是最保守的,但是这将使吞吐量变得很低,特别是消费者连接延迟很严重的情况下
消息持久化
我们已经学会了如何确保即使消费者死亡,任务也不会丢失。但是如果 RabbitMQ 服务器停止,我们的任务仍然会丢失。即 MQ 系统出现问题,整个消息将全部丢失(消息默认保存在内存中)。想要让消息不会丢失,需要将队列和消息都变为持久的
队列持久化
之前创建的队列都是非持久化的, 如果将 rabbitmq 重启,该队列就会被删除掉,要实现队列持久化 需要在声明队列的时候把 durable 参数设置为持久化,如下所示:
1
2
| boolean durable = true;
channel.queueDeclare(ACK_QUEUE_NAME, durable, false, false, null);
|
🎶需要注意的是:如果之前声明的队列不是持久化的,需要先将原队列先删除,随后重新创建一个持久化的队列,才能保证原本的队列变为持久队列。其实相当于重新创建了一个持久化队列。这个时候即时重启 rabbitmq 持久队列也依然存在
消息持久化
保证队列持久化后,现在我们需要将我们的消息标记为持久性。通过将 MessageProperties(使用 BasicProperties 实现)设置为值 PERSISTENT_TEXT_PLAIN
1
2
3
4
5
| import com.rabbitmq.client.MessageProperties;
channel.basicPublish("", "task_queue",
MessageProperties.PERSISTENT_TEXT_PLAIN,
message.getBytes());
|
🎶消息持久化注意事项
将消息标记为持久性并不能完全保证消息不会丢失。虽然它告诉 RabbitMQ 将消息保存到磁盘,但是当 RabbitMQ 接受一条消息并且还没有保存它时(当消息刚准备存储在磁盘的时候,但是还没有存储完,消息还在缓存的一个间隔点),仍然存在很短的时间间隔,这一段时间内如果 MQ 出现故障仍然可能导致消息的丢失。此外,RabbitMQ 不会对每条消息都执行 fsync(2) —— 它可能只是保存到缓存中,而不是真正写入磁盘。
📓如果需要更强持久性保证,可以使用发布者确认模式
附录
RabbitMQ 入门:工作队列(Work Queue)
官方文档——WorkQueues