目录 概述 基础查询 查询列表是查询函数 查询列表起别名 字段拼接 查看表的结构 条件查询 关系表达式筛选 逻辑表达式筛选 模糊查询 like 常见的通配符 in between A AND B is null 字段控制查询(dintinct) 排序查询 基本格式 按照单个字段排序 按照表达式排序 按照别名排序 按照函数的结果排序 按照多个字段排序 常见函数(单行函数) 字符函数 数学函数 日期函数 流程控制函数 分组函数 分组查询 简单分组查询案例 分组前筛选案例 分组后筛选案例 分组后排序案例 按照多个字段分组案例 连接查询 sql92 标准 等值连接 非等值连接 自连接 sql99 标准 等值连接 非等值连接 自连接 外连接 交叉连接 子查询 子查询在 where 或 having 后面 单行子查询 多行子查询 子查询在 SELECT 后面 子查询在 FROM 后面 放在 exists 后面 分页查询 分页查询基本框架 分页显示公式 联合查询 概述 ❓ 什么是 DQL 数据查询语言?
数据库的核心操作之一就是提供给使用者进行查询,和基础编程语言的语法相同,向数据库中查询相关的数据,也需要遵从一定的语法规范,这种语法规范而后就形成了 DQL 语言,所以本文主要考虑如何使用 DQL 语言,从数据库查询出满意的数据。
基础查询 ✨ 查询语句具有以下特点:
查询结果集,返回的是一个虚拟表,select 查询列表类似于 Java 中的 sout 执行顺序:先from 后select 查询列表可以是:字段、表达式、常量、函数等 1 2 3 4 5 6 7 8 #查询列表是常数 SELECT 100 ;#查询列表是表达式,常数不需要加单引号,如果是字段或字符需要加单引号 SELECT 100 % 2 ;#查询列表是字段 SELECT `first_name`,`last_name`,`email` FROM `employees` ;#查询列表是函数 SELECT DATABASE();
❓ 如何查找一个表的全部字段?
1 SELECT * FROM `employees`; #此种方法虽然便于书写但是语意不明确
查询列表是查询函数 🎶 查询列表是一个函数,表示查询时调用函数,并获取函数的返回值
1 2 3 SELECT DATABASE(); #查看当前正在使用的数据库SELECT VERSION(); #查看MySQL的版本SELECT USER (); #查看当前登录数据库的用户
查询列表起别名 进行查询时,表中字段名表达的语义不够直接、明确,可以使用别名对查询的字段重命名。设置字段别名主要有两种方式 :使用 AS 关键字和使用空格分隔
1 2 3 4 # 方式一:使用AS 关键字 SELECT USER () AS '姓 名' ; #此时返回虚拟表中的列名,从user ()变为姓名# 方式二:使用空格分隔 SELECT USER () '姓 名' ;
字段拼接 ❓如果想将查询结果中两列结果合并,如何进行?
✨ +在不同场景下的不同作用:
Java 中有两种作用:加法运算 以及字符串拼接 MySQL 中,只有一种作用:进行加法运算 🎶 MySQL 中+运算结果
加号两边操作数类型 结果 举例 数值型 数值 100+1.5 ===> 101.5 其中一个操作数为字符型 字符型看作 0,之后进行加法运算 ‘张三’+100 ===> 100 其中一个操作数为 null null null+100 ===> null
1 SELECT CONCAT(first_name,last_name) FROM employees;
查看表的结构 1 2 DESC employees;show columns from employees;
条件查询 1 SELECT 查询列表 FROM 表名 WHERE 筛选条件;
✨特点:
执行顺序:FROM–>WHERE–>SELECT 筛选条件可以是关系表达式: >, >=, <, <=, =, <>,虽然!=也可以,但是不推荐 筛选条件可以是逻辑表达式:and,or,not 模糊查询:like,in,between and,is null 关系表达式筛选 案例 1:查询部门编号不是 100 的员工信息
1 2 3 SELECT * FROM employeesWHERE department_id <> 100 ;
#案例 2:查询工资<15000 的姓名、工资
1 2 3 SELECT CONCAT(last_name, first_name) AS '姓 名' ,salaryFROM employeesWHERE salary< 15000 ;
逻辑表达式筛选 案例 1:查询部门编号不是 50-100 之间员工姓名、部门编号、邮箱
1 2 3 4 5 6 7 8 #方式1 : SELECT last_name,department_id,emailFROM employeesWHERE department_id < 50 OR department_id> 100 ;#方式2 : SELECT last_name,department_id,emailFROM employeesWHERE NOT (department_id>= 50 AND department_id<= 100 );
案例 2:查询奖金率>0.03 或者 员工编号在 60-110 之间的员工信息
1 2 SELECT * FROM employeesWHERE commission_pct> 0.03 OR (employee_id>= 60 AND employee_id<= 100 );
模糊查询 模糊查询主要进行模糊搜索依赖于 like 、in 等关键字以及一些其他的符号
like like 关键字通常和通配符搭配使用,对字符型数据进行部分匹配查询
1 2 WHERE 字段 LIKE '匹配字符串' ;WHERE 字段 NOT LIKE '匹配字符串' ;
常见的通配符 通配符 含义 _(下划线) 任意单个字符 %(百分号) 任意多个字符,0-多个
案例 1:查询姓中包含字符 a 的员工信息
1 SELECT * FROM employees WHERE last_name LIKE '%a%' ;
案例 2:查询姓中包含最后一个字符为 e 的员工信息
1 SELECT * FROM employees WHERE last_name LIKE '%e' ;
案例 3:查询姓中包含第一个字符为 e 的员工信息
1 SELECT * FROM employees WHERE last_name LIKE 'e%' ;
案例 4:查询姓中包含第三个字符为 x 的员工信息
1 SELECT * FROM employees WHERE last_name LIKE '__x%' ;
案例 5:查询姓名中包含第二个字符为_的员工信息
1 2 3 4 #方式一,默认选用\作为转义字符 SELECT * FROM employees WHERE last_name LIKE '_\_%' ;#方式二,自定义转义字符 SELECT * FROM employees WHERE last_name LIKE '_$_%' ESCAPE '$' ;
in 🎶 in 关键字用于查询某字段的值是否属于指定的列表之内
1 2 WHERE 字段 IN (a,b,c);WHERE 字段 NOT IN (a,b,c);
案例 1:查询部门编号是 30/50/90 的员工名、部门编号
1 2 3 SELECT * FROM employees WHERE department_id IN (30 ,50 ,90 );SELECT * FROM employeesWHERE department_id= 30 OR department_id= 50 OR department_id= 90 ;
案例 2:查询工种编号不是 SH_CLERK 或 IT_PROG 的员工信息
1 2 SELECT * FROM employees WHERE job_id NOT IN ('SH_CLERK' ,'IT_PROG' );SELECT * FROM employees WHERE NOT (job_id = 'SH_CLERK' OR job_id= 'IT_PROG' );
between A AND B 🎶 betweem and 关键字用于判断某个字段的值是否介于[A,B]之间
1 2 WHERE 字段 between minNUmber AND maxNumber;WHERE 字段 NOT between minNUmber AND maxNumber;
案例 1:查询部门编号是 30-90 之间的部门编号、员工姓名
1 2 SELECT * FROM employees WHERE department_id BETWEEN 30 AND 90 ;SELECT * FROM employees WHERE department_id>= 30 AND department_id<= 90 ;
案例 2:查询年薪不是 100000-200000 之间的员工姓名、工资、年薪
1 2 SELECT * FROM employeesWHERE salary* (12 + IFNULL(commission_pct,0 )) NOT BETWEEN 10000 AND 20000 ;
is null 🎶 is null 用于判断当前字段是否为空
案例 1:查询没有奖金的员工信息
1 SELECT * FROM employees WHERE commission_pct IS NULL ;
案例 2:查询有奖金的员工信息
1 SELECT * FROM employees WHERE commission_pct IS NOT NULL ;
🎶 =与IS的区别:
=:只能判断普通的内容IS只能判断 NULL 值<=>安全等于,既能判断普通内容,又能判断 NULL 值,符合表达意义不明确,不推荐使用 字段控制查询(dintinct) 🎶 distinct 关键字用于去除重复记录
需求:查询员工涉及到的部门编号有哪些
1 SELECT DISTINCT department_id FROM employees;
排序查询 基本格式 1 SELECT 查询列表,FROM 表名,[WHERE 筛选条件],ORDER BY 排序列表 < ASC | DESC >
✨特点:
执行顺序: FROM --> WHERE --> SELECT --> ORDER BY (所以排序列表可以使用别名) 排序列表可以是:单个字段、多个字段、表达式、函数、以及这些列表的组合 排序方式有两种:升序(ASC,默认行为)、降序(DESC) 按照单个字段排序 案例 1:将员工编号>120 的员工信息进行工资的升序(降序)
1 2 select * from employees where employee_id> 120 ORDER BY salary;SELECT * FROM employees WHERE employee_id> 120 ORDER BY salary DESC ;
按照表达式排序 案例 1:对有奖金的员工,按年薪降序
1 2 3 4 5 6 7 select * , salary * (1 + ifnull(commission_pct, 0 )) as '年薪' from employees where commission_pct is not null order by salary * (1 + ifnull(commission_pct, 0 )) desc ;
按照别名排序 案例 1:对有奖金的员工,按年薪降序
1 2 3 4 5 6 7 SELECT * , salary * (1 + commission_pct) AS '年薪' FROM employees WHERE commission_pct IS NOT NULL ORDER BY 年薪 DESC ;
按照函数的结果排序 案例 1:按姓名的字数长度进行升序
1 SELECT * FROM employees ORDER BY LENGTH(last_name);
按照多个字段排序 案例 1:查询员工的姓名、工资、部门编号,先按工资升序,再按部门编号降序
1 2 3 4 5 6 7 8 SELECT last_name, salary, department_id FROM employees ORDER BY salary ASC , department_id DESC ;
常见函数(单行函数) 🎶函数类似于 JAVA 中的方法,为了解决某个问题,将编写的一系列命令集合封装在一起,对外仅暴露方法名,供外部调用。常见函数拥有如下几类:
字符函数 主要记录对字符串进行操作的常用函数
函数 作用 CONCAT() 拼接字符串 LENGTH() 获取字符长度 CHAR_LENGTH() 获取字符个数 SUBSTRING() 截取子串,MySQL 中子串的开始索引为1 INSTR() 获取字符第一次出现的索引 TRIM() 去除前后指定的字符,默认是空格 LPAD() 按照指定长度,分别对字符串的左端,补充字符 RPAD() 按照指定长度,分别对字符串的右端,补充字符 UPPER() 将字符变为大写 LOWER() 将字符变为小写 STRCMP() 比较两个字符大小,使用 ASCII 码值比较,前者减后者 LEFT() 从左边截取子串 RIGHT() 从右边截取子串
1 2 #将多个字符串进行拼接,如果其中一个字符是null ,拼接结果就是null CONCAT(str1,str2,...)
1 2 ELECT length('hello,世界' ); #结果: 12
1 2 SELECT CHAR_LENGTH ('hello,世界' );#结果: 8
1 2 3 4 5 SUBSTRING (str,pos,len); #JAVA函数格式,从str串的pos位置截取len长度的子串,SUBSTRING (str,pos); #JAVA函数格式,截取str串从pos开始到结尾的子串SUBSTRING (str FROM pos);#SQL 函数格式,作用同格式2 SELECT SUBSTRING ('hello,世界' ,2 );#结果: ello,世界
1 2 SELECT INSTR('hello world ,oh! hohoho' ,'o' );#结果: 5
1 2 3 4 5 6 TRIM (str);TRIM (['removStr' FROM ]str);SELECT TRIM (' hello world ' );#结果: hello world SELECT TRIM ('x' FROM 'xxxxxxhelloxxxxxworldxxxxxx' );#结果: helloxxxxxworld
1 2 3 4 5 6 LPAD(str,len,padstr); SELECT LPAD('hello world' ,15 ,'x' );#结果: xxxxhello world RPAD(str,len,padstr); SELECT RPAD('hello world' ,15 ,'x' );#结果: hello worldxxxx
1 2 SELECT UPPER ('hello world' );#结果: HELLO WORLD
1 2 select strcmp('a' ,'b' );#结果: -1
1 2 3 4 SELECT LEFT ('hello world' ,1 );#结果: h SELECT RIGHT ('hello world' ,1 );#结果: d
数学函数 数学函数用来对数学返回结果进行操作
函数 作用 ABS() 求绝对值 CEIL() 向上取整 FLOOR() 向下取整 ROUND() 四舍五入取整 TRUNCATE() 小数截断 MOD() 取余
1 2 SELECT ROUND(1.55 );#结果: 2
1 2 3 TRUNCATE (X,D); #将X的第D位小数后的精度丢弃SELECT TRUNCATE (1.55 ,1 );#结果: 1.5
1 2 SELECT MOD (10 ,3 );#结果: 1
日期函数 日期函数用来进行相关的日期操作
函数 作用 NOW() 返回现在的年月日以及时间,NOW() = CONCAT( CURDATE() ,CURTIME() ) CURDATE() 返回当前日期 CURTIME() 返回当前时间 DATEDIFF() 检查两时间的差距,使用前者时间减去后者时间,算出两时间节点间的差值 DATE_FORMAT() 输出特定格式的时间类型 STR_TO_DATE() 按指定格式解析字符串,将字符类型转为日期类型,而后可以进行关系处理
1 2 SELECT NOW();#2021 -03 -04 08 :45 :09
1 2 SELECT CURDATE();#2021 -03 -04
1 2 SELECT CURTIME();#08 :46 :12
1 2 SELECT DATEDIFF('1998-7-20' ,'2021-3-3' );#-8262
1 2 SELECT DATE_FORMAT('1998-7-20' ,'%Y年%M月%d日 %H小时%i分钟%s秒' ) 出生日期;## 1998 年July月20 日 00 时00 分钟00 秒
1 SELECT * FROM employees WHERE hiredate< STR_TO_DATE('3/15 1998' ,'%m/%d %Y' )
流程控制函数 流程控制函数类似于 Java 中的流程控制语句
函数 作用 IF() 根据条件执行相应的表达式 IFNULL(表达式 1,表达式 2) 如果表达式 1 为 null,则显示表达式 2,否则显示表达式 1 CASE 函数 与 JAVA 中的switch类似,但 MySQL 中的 CASE 函数主要有两种用法
1 2 3 SELECT IF(100 > 9 ,'正确' ,'错误' );#需求:如果有奖金,则显示最终奖金,如果没有,则显示0 SELECT IF(commission_pct IS NOT NULL ,salary* (1 + commission_pct),0 ) FROM employees;
1 2 3 4 5 6 7 # case 此格式功能与switch功能相似,根据不同值进行处理 CASE 表达式WHEN 值1 THEN 结果1 WHEN 值2 THEN 结果2 ... ELSE 结果n #等价于Java switch 中的 default 子句END
案例:部门编号是 30,工资显示为 2 倍,部门编号是 50,工资显示为 3 倍,部门编号是 60,工资显示为 4 倍
1 2 3 4 5 6 7 8 select department_id,salary,case department_idwhen 30 then salary* 2 when 50 THEN salary* 3 when 60 THEN salary* 4 else salaryend as 'NewSalary' from employees;
1 2 3 4 5 6 7 # 方式二:类似于多重IF语句,实现区间判断 CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 ... ELSE 结果nEND
案例:如果工资>20000,显示级别 A;工资>15000,显示级别 B;工资>10000,显示级别 C,否则,显示 D
1 2 3 4 5 6 7 8 SELECT CASE WHEN salary> 20000 THEN 'A' WHEN salary> 15000 THEN 'B' WHEN salary> 10000 THEN 'C' ELSE 'D' END salaryRankFROM employees;
分组函数 说明:分组函数往往用于实现将一组数据进行统计计算,最终得到一个值,又称为聚合函数或统计函数
函数 作用 sum(字段名) 求和 avg(字段名) 求平均值 max(字段名) 求最大值 min(字段名) 求最小值 count(字段名) 计算非空字段值的个数
案例 1 :查询员工信息表中,所有员工的工资和、工资平均值、最低工资、最高工资、有工资的个数
1 2 select sum (salary),avg (salary),min (salary),max (salary),count (salary)from employees;
查询 emp 表中记录数
1 select count (* ) from employees; #如果一行数据存在非空值,则count (* )就统计一次
需求:查询有员工的部门个数
1 SELECT COUNT (DISTINCT department_id)FROM employees; #count搭配distinct 进行分组统计
分组查询 1 2 3 4 SELECT 查询列表 FROM 表名 WHERE 筛选条件GROUP BY 分组列表having 分组后筛选ORDER BY 排序列表
✨分组查询特点:
执行顺序:FROM --> WHERE --> GROUP BY --> HAVING --> SELECT --> ORDER BY 查询列表往往是:分组函数和被分组的字段 分组查询中对条件的筛选分为两类:分组前筛选与分组后筛选 分组筛选时机 筛选的基表 使用的关键字 位置 分组前筛选 FROM 语句中包括的表 WHERE GROUP BY 的前面 分组后筛选 分组后的结果集 HAVING GOUPR BY 的后面
🎶 分组函数不能放在 WHERE 语句中 ;如果一个筛选条件同时出现在两个筛选条件中,将此条件放在分组前筛选最佳,这样能够有效的提高查询效率
简单分组查询案例 案例 1:查询每个工种的员工平均工资
1 2 3 SELECT AVG (salary),job_idFROM employeesGROUP BY job_id;
案例 2:查询每个领导的手下人数
1 2 3 4 SELECT COUNT (* ),manager_idFROM employeesWHERE manager_id IS NOT NULL GROUP BY manager_id;
分组前筛选案例 案例 1:查询邮箱中包含 a 字符的 每个部门的最高工资
1 2 3 4 SELECT MAX (salary),department_idFROM employeesWHERE email LIKE '%a%' AND department_id IS NOT NULL GROUP BY department_id;
案例 2:查询每个领导手下有奖金的员工的平均工资
1 2 3 4 SELECT manager_id,AVG (salary)FROM employeesWHERE commission_pct IS NOT NULL GROUP BY manager_id
分组后筛选案例 案例 1:查询哪个部门的员工个数>5
1 2 3 4 SELECT COUNT (* ),department_idFROM employeesGROUP BY department_idHAVING COUNT (* )> 5 ;
案例 2:每个工种有奖金的员工的最高工资>12000 的工种编号和最高工资
1 2 3 4 5 SELECT MAX (salary),job_idFROM employeesWHERE commission_pct IS NOT NULL GROUP BY job_idHAVING MAX (salary)> 12000 ;
案例 3:领导编号>102,每个领导手下的最低工资大于 5000 的最低工资
1 2 3 4 5 SELECT MIN (salary),manager_idFROM employeesWHERE manager_id > 102 GROUP BY manager_idHAVING MIN (salary)> 5000 ;
分组后排序案例 案例:查询没有奖金的员工的最高工资>6000 的工种编号和最高工资,按最高工资升序
1 2 3 4 5 6 SELECT MAX (salary),job_idFROM employeesWHERE commission_pct IS NULL GROUP BY job_idHAVING MAX (salary)> 6000 ORDER BY MAX (salary) ASC ;
按照多个字段分组案例 案例:查询每个工种每个部门的最低工资,并按最低工资降序
1 2 3 4 select min (salary),job_id,department_idfrom employeesgroup by job_id,department_idorder by min (salary);
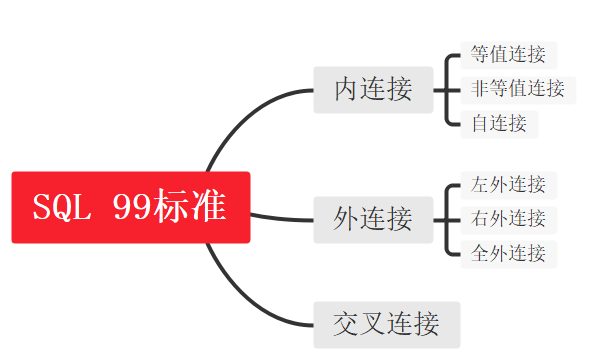
连接查询 连接查询又称为多表查询,当查询语句涉及到的字段来自于多个表时,就会用到连接查询,目前存在的连接查询有两种,分别是sql 92标准与sql 99标准
sql92 标准 仅支持内连接 ,内连接的格式如下:
1 2 3 4 5 6 7 SELECT 查询列表FROM 表1 别名,表2 别名WHERE 连接条件AND 筛选条件GROUP BY 分组列表HAVING 分组后筛选ORDER BY 排序列表
✨sql 92 标准下内连接特点: 执行顺序: FROM --> WHERE --> AND --> GROUP BY --> HAVING --> SELECT --> ORDER BY
等值连接 ✨等值连接特点:
多表等值连接的结果为多表的交集部分 n 表连接,至少需要 n-1 各连接条件 多表的顺序没有要求 一般需要为表起别名,加强程序的语义性 可以搭配前面介绍的所有子句使用,比如排序、分组、筛选 案例 1:查询女神名和对应的男神名
1 2 3 SELECT NAME,boyNameFROM boys,beautyWHERE beauty.boyfriend_id= boys.id;
案例 2:查询员工名和对应的部门名
1 2 3 SELECT last_name,department_nameFROM employees,departmentsWHERE employees.`department_id`= departments.`department_id`;
案例 3:查询每个城市的部门个数
1 2 3 4 SELECT COUNT (* ) 个数,cityFROM departments d,locations lWHERE d.`location_id`= l.`location_id`GROUP BY city; #连接后进行分组查询
案例 4:查询每个工种的工种名和员工的个数,并且按员工个数降序
1 2 3 4 5 SELECT job_title,COUNT (* )FROM employees e,jobs jWHERE e.`job_id`= j.`job_id`GROUP BY job_titleORDER BY COUNT (* ) DESC ; #连接后进行分组查询且排序
👴对表起别名总是有好处的,可以提高语句的简洁度,区分多个重名的字段;如果对表起了别名 ,则查询的字段就不能使用原来的表名进行条件筛选
1 2 3 4 5 6 7 8 9 #如此就会出错,如果存在别名,就不能使用原表名 SELECT e.last_name,e.job_id,j.job_titleFROM employees e,jobs jWHERE employees.`job_id`= jobs.`job_id`;#如此,可以正确查询 SELECT e.last_name,e.job_id,j.job_titleFROM employees e,jobs jWHERE e.`job_id`= j.`job_id`;
非等值连接 非等值连接中,一个表中的数值落在于另一个表中两列的数值范围中,以此来构成连接
案例 1:查询员工的工资和工资级别
1 2 3 4 SELECT e.`salary`,sg.`grade`FROM employees AS e,sal_grade AS sgWHERE e.`salary` BETWEEN sg.`min_salary` AND sg.`max_salary`;#使用BETWEEN...AND...进行非等值间的连接
自连接 查询表来自于自身,自身与自身的连接 称之为自连接
案例:查询员工名和上级的名称
1 2 3 SELECT e.employee_id,e.last_name,m.employee_id,m.last_nameFROM employees e,employees mWHERE e.`manager_id`= m.`employee_id`;
sql99 标准 sql99 支持内连接、外连接(左外和右外)+交叉连接
🎶SQL 99 使用JOIN关键字代替了之前的逗号,并且将连接条件和筛选条件进行了分离,提高了阅读性
1 2 3 4 5 6 7 SELECT 查询列表 FROM 表名1 [AS ] 别名[INNER ] JOIN 表名2 [AS ] 别名 ON 连接条件WHERE 筛选条件GROUP BY 分组列表HAVING 分组后筛选ORDER BY 排序列表
等值连接 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #案例1 :查询员工名和部门名 SELECT last_name,department_nameFROM departments dINNER JOIN employees eON e.department_id = d.department_id;#案例2 :查询部门编号> 100 的部门名和所在的城市名 SELECT department_name,cityFROM departments dJOIN locations lON d.`location_id` = l.`location_id`WHERE d.`department_id`> 100 ; #添加筛选条件#案例3 :查询每个城市的部门个数 SELECT COUNT (* ) 部门个数,l.`city`FROM departments dJOIN locations lON d.`location_id`= l.`location_id`GROUP BY l.`city`; #添加分组筛选#案例4 :查询部门中员工个数> 10 的部门名,并按员工个数降序 SELECT COUNT (* ) 员工个数,d.department_nameFROM employees eJOIN departments dON e.`department_id`= d.`department_id`GROUP BY d.`department_id`HAVING 员工个数> 10 ORDER BY 员工个数 DESC ; #添加分组、筛选、排序#案例5 : 选择city在Toronto工作的员工的last_name , job_id , department_id , department_name SELECT last_name , job_id , department_id , department_nameFROM employees eJOIN departments d ON e.`department_id` = d.`department_id`JOIN locations l ON d.`location_id` = l.`location_id` #多表连接,使用多次join 语句WHERE city = 'Toronto' ;#案例6 : 查询每个工种、每个部门的部门名、工种名和最低工资 select j.`job_title`,d.`department_name`,min (salary)from employees as einner join jobs as j on e.`job_id` = j.`job_id`inner join departments as d on e.`department_id`= d.`department_id`group by j.`job_id`,e.`department_id`
非等值连接 1 2 3 4 5 6 7 #案例:查询部门编号在10 -90 之间的员工的工资级别,并按级别进行分组 SELECT COUNT (* ) 个数,gradeFROM employees eJOIN sal_grade gON e.`salary` BETWEEN g.`min_salary` AND g.`max_salary`WHERE e.`department_id` BETWEEN 10 AND 90 GROUP BY g.grade;
自连接 1 2 3 4 5 #案例:查询员工名和对应的领导名 SELECT e.`last_name`,m.`last_name`FROM employees eJOIN employees mON e.`manager_id`= m.`employee_id`;
外连接 ✨外连接特点
查询结果为主表中所有的记录,如果从表有匹配项,则显示匹配项;如果从表没有匹配项,则显示 null 应用场景:一般用于查询主表中有但从表没有的记录 外连接分主从表,两表的顺序不能任意调换 左连接的话、left join 左边为主表 右连接的话、right join 右边为主表 全连接,将两个表结合在一起,另一方表未出现的数据,均使用NULL代替,MySQL 不支持 1 2 3 4 5 SELECT 查询列表FROM 表1 别名LEFT | RIGHT | FULL [OUTER ] JOIN 表2 别名ON 连接条件WHERE 筛选条件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #案例1 :查询所有女神记录,以及对应的男神名,如果没有对应的男神,则显示为null select g.`name`,b.`boyName`from beauty as gleft outer join boys as b on g.`boyfriend_id`= b.`id`;#女生为主表select g.`name`,b.`boyName`from boys as bleft outer join beauty as g on g.`boyfriend_id`= b.`id;`#男生为主表#案例2 :查哪个女神没有男朋友 select g.`name`from beauty as gleft outer join boys b on g.`boyfriend_id`= b.`id`where b.`boyName` is null ;#案例3 :查询哪个部门没有员工,并显示其部门编号和部门名 SELECT d.`department_id`,d.`department_name`FROM departments dLEFT JOIN employees e ON d.`department_id` = e.`department_id`WHERE e.`employee_id` IS NULL GROUP BY d.`department_id`;#案例4 :查询部门名为 SAL 或 IT 的员工信息 SELECT d.* ,e.* FROM departments dLEFT JOIN employees e ON d.`department_id` = e.`department_id`WHERE d.`department_name` = 'SAL' OR d.`department_name`= 'IT' ;
👴使用外连接时一定要清楚主表和从表,以及那些属性可以为空进行判断
交叉连接 🎶交叉连接返回的结果,是被连接的两个表中所有数据行的笛卡尔积
1 2 3 #案例1 : Department表中有4 个部门,employee表中有4 个员工,那么,交叉连接的结果就有16 条数据 SELECT * FROM 表1 CROSS JOIN 表2 ;
👴实际开发中,不经常使用交叉连接
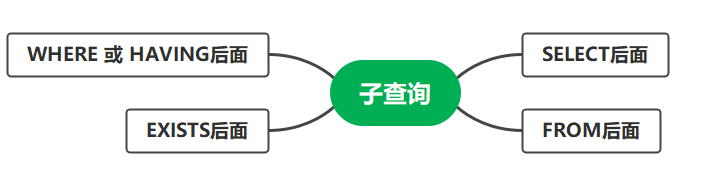
子查询 🎶当一个查询语句中又嵌套了另一个完整的SELECT语句,则被嵌套的 SELECT 语句称为子查询或内查询,外面的 SELECT 语句称为主查询或外查询
✨子查询特点:
子查询放在条件中,要求必须放在条件的右侧 子查询一般放在小括号中 子查询的执行优先于主查询 单行子查询对应单行操作符(<,<=,>,>=,=,<>) 多行子查询对应多行操作符(any/some,all,in) 根据子查询所在位置不同,可以有以下的分类方式:
子查询在 where 或 having 后面 这种方式的子查询又进一步可以分为:单行子查询以及多行子查询
单行子查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #案例1 :谁的工资比Abel高? SELECT `last_name`, salary FROM employees WHERE salary > (SELECT e.`salary` FROM employees AS e WHERE e.`last_name` = 'Abel' ); #案例2 :返回job_id与141 号员工相同,salary比143 号员工多的员工姓名,job_id 和工资 SELECT last_name,job_id,salaryFROM employeesWHERE job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 ) AND salary> ( SELECT salary FROM employees WHERE employee_id = 143 ); #案例3 :返回公司工资最少的员工的last_name,job_id和salary select last_name,job_id,salaryfrom employeeswhere salary = ( SELECT MIN (salary) FROM employees AS e); #案例4 :查询最低工资大于50 号部门最低工资的部门id和其最低工资 SELECT MIN (salary),department_idFROM employeesGROUP BY department_idHAVING MIN (salary)> ( SELECT MIN (salary) FROM employees WHERE department_id = 50 );
多行子查询 🎶 多行操作符:in、any/some:判断某字段是否满足其中任意一个数值以及 all:判断某字段的值是否满足里面所有的数值
1 2 3 x in (1 ,2 ,3 ,4 ) x> any (10 ,20 ,30 ,40 ) #只要大于最少值即可 x> all (10 ,20 ,30 ,40 ) #需要大于最大值
案例 1:返回 location_id 是 1400 或 1700 的部门中的所有员工姓名
1 2 3 4 SELECT last_name FROM employeesWHERE department_id IN (SELECT department_id FROM departments WHERE location_id IN (1400 , 1700 ));
案例 2:返回其它部门中比 job_id 为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id 以及 salary
1 2 3 4 5 6 7 SELECT employee_id,last_name,job_id,salaryFROM employeesWHERE salary< ANY ( SELECT DISTINCT salary FROM employees WHERE job_id = 'IT_PROG' );
子查询在 SELECT 后面 1 2 3 4 5 #案例;查询部门编号是50 的员工个数 SELECT (SELECT COUNT (* )FROM employeesWHERE department_id= 50 );
子查询在 FROM 后面 1 2 3 4 5 6 7 #案例:查询每个部门的平均工资的工资级别 select grade_levelfrom job_grades inner join (select avg (salary) avgs,department_idfrom employeesgroup by department_id) ag on ag.avgs between lowest_sal and highest_sal
放在 exists 后面 1 2 #案例1 :查询有无名字叫“张三丰”的员工信息 select exists (SELECT last_name FROM employees WHERE last_name= '张三丰' );
分页查询 当页面上的数据,一页显示不全,则需要分页显示,基本格式如下:
分页查询基本框架 1 2 3 4 5 6 7 8 9 SELECT 查询列表FROM 表1 别名JOIN 表2 别名ON 连接条件WHERE 筛选条件GROUP BY 分组列表HAVING 分组后筛选条件ORDER BY 排序列表LIMIT 起始条目,显示的条目数;
✨ 分页查询特点
执行顺序: FROM --> JOIN --> ON --> WHERE --> GROUP BY --> HAVING --> SELECT --> ORDER BY --> LIMIT 起始条目索引默认为0 分页显示公式 1 2 #假如要显示的页数时page,每页显示的条目数为size SELECT * FROM employees LIMIT (page-1 )* size,size;
案例 1:查询员工信息表的前 5 条
1 2 3 select * from employees limit 0 ,5 ;#等价于 SELECT * FROM employees LIMIT 5 ;
案例 2:查询有奖金的,且工资较高的第 11 名到第 20 名
1 2 3 SELECT * FROM employees WHERE commission_pct IS NOT NULL ORDER BY salary DESC LIMIT 10 ,10 ;
联合查询 当查询结果来自于多张表,单多张表之间没有关联,这个适合就需要使用联合查询,也成为 union 查询
1 2 3 SELECT 查询列表 FROM 表1 WHERE 筛选条件UNION SELECT 查询列表 FROM 表2 WHERE 筛选条件
✨联合查询特点
多条待联合的查询语句的查询列数必须一致,查询类型、字段含义最好一致 union:默认去重查询,union all:实现全部查询,包含重复项 案例:查询所有国家的年龄>20 岁的用户信息
1 2 SELECT * FROM usa WHERE uage > 20 UNION SELECT * FROM chinese WHERE age > 20 ;
案例 2:union 自动去重/union all 可以支持重复项
1 2 3 SELECT 1 ,'重复项1' UNION ALL SELECT 1 ,'重复项1'