程序的内存布局
目录
¶应用程序的内存空间
✨一般而言,应用程序使用的内存空间里有如下默认的区域:
| 区域 | 含义 |
|---|---|
| 栈 | 栈用于维护函数调用的上下文,没有栈,函数调用就无法实现,栈通常在用户空间的最高地址处分配,一般有数兆字节的大小 |
| 堆 | 堆用来容纳应用程序动态分配的内存区域,当程序使用 malloc 或者 new 分配内存的时候,得到的内存来自堆。堆通常存在于栈的下方(低地址方向),某些时候,堆也可能没有固定统一的存储区域,堆一般比栈大很多,可以有几十至数百兆字节的容量 |
| 可执行文件映像 | 存储着可执行文件在内存里的映像,由装载器在装载时将可执行文件的内存读取或映射到这里 |
| 保留区 | 保留区并不是一个单一的内存区域,而是对内存中受到保护而禁止访问的内存区域的总称:例如大多数操作系统中,极小的地址通常都是不允许访问的,如 NULL,C 语言将无效指针赋值为 0 也是这个考虑 |
| 动态链接库映射区 | 动态链接库映射区用于映射装载的动态链接库。在 Linux 下,如果可执行文件依赖其它共享库,那么系统就会为它在从 0x40000000 开始的地址分配相应的空间,并将共享库载入该空间 |
| 代码段 | 存放程度运行的可执行指令集合 |
| 初始化数据段 | 也称为数据段,这里存放程序运行前已经完成初始化工作的字段 |
| 未初始化数据段 | 也称为 BSS 段,由内核进行最开始的默认初始化,存放的是程序中的全局变量和静态变量 |
下图就是 Linux 下一个进程里典型的内存布局:
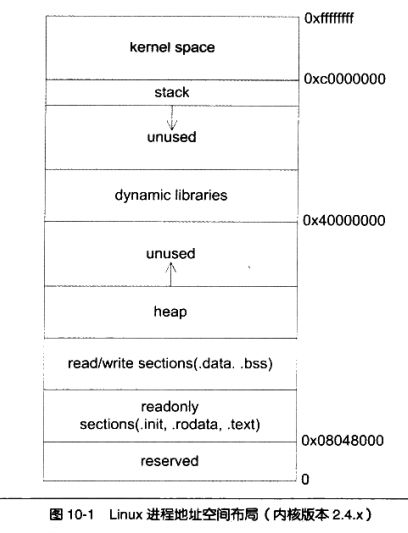
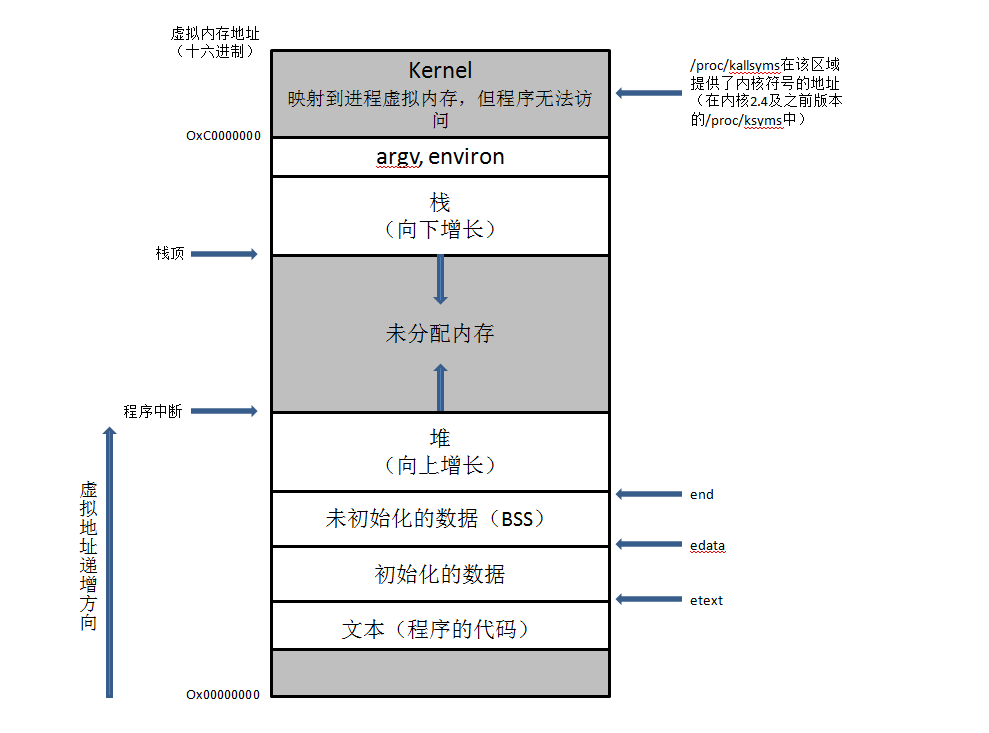
接下来简单介绍其中比较重要的几个组件
¶代码段
代码段中存放可执行的指令,存在程序内存的最底层,是为了保证不会因为堆栈溢出被覆盖(从上图可以看出)。
¶初始化数据段
初始化数据段有时就称之为数据段。数据段是一个程序虚拟地址空间的一部分,包括全局变量和静态变量,这些变量在编程时就已经被初始化。数据段是可以修改的,不然程序运行时变量就无法改变了,这一点和代码段不同
¶未初始化数据段
未初始化数据段有时称之为 BSS 段,BSS 是英文 Block Started by Symbol 的简称,BSS 段属于静态内存分配。存放在这里的数据都由内核进行零初始化。
¶栈
栈是用来存储程序初期设定的变量的,这些变量在程序执行之前就要准备好。因此栈要放在程序内存的头部并且位置固定,否则程序就不知道该到那里去找这些变量。而程序的运行结果往往是不能预先确定的,所以把堆放在程序中内存的后部以便可以提供足够的内存保存运算结果。在经典的操作系统里,栈总是向下增长的
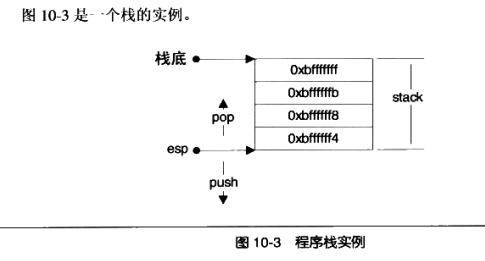
👍栈在程序运行中具有举足轻重的地位,栈保存了一个函数调用所需要的维护信息,这常常被称为栈帧(Stack Frame)或活动记录(Activate Record),栈帧一般包括如下几方面内容
😣使用栈也会存在非常多缺点:
¶堆
❓这里说的堆和数据结构中的堆有什么关系?
在进程内存中,使用堆表示分配的一系列内存,而在数据结构中,堆则表示一种特定的数据结构,这两者没有必然的联系,内存中的堆更像是一种线性表结构
Several authors began about 1975 to call the pool of available memory a “heap.” But in the present series of books, we will use that word only in its more traditional sense related to priority queues. (Fundamental Algorithms, 3rd ed., p. 435)
❓为什么需要堆?
堆是一款巨大的内存空间,常常占据整个虚拟空间的绝大部分,在这片空间里,程序可以请求一块连续的内存,并自由地使用,这块内存在程序主动放弃之前都活一直保持有效。
❓malloc到底是怎么实现的尼?
相对于栈,堆内存面临着一个稍微复杂的行为模式:在任意时刻,程序可能发出请求,要么申请一段内存,要么释放一段已经申请过的内存,而且申请的大小从几个字节到数 GB 都是有可能的,我们不能假设程序会一次申请多少堆空间,因此,堆的管理显得较为复杂
¶堆栈疑问
本小节主要记录我对程序内存中堆栈存在的诸多问题
❓为什么要将堆和栈区分出来?
❓不能全用堆或者全用栈吗?
❓在 Java 语言中,堆中存什么?栈中存什么?
❓那么为什么在 Java 中不将所有的东西都放在堆中,而是一部分数据放在堆中?
因为基本数据类型占用的空间一般是1~8个字节,需要空间比较少,而且因为是基本类型,所以不会出现动态增长的情况——长度固定,因此栈中存储就够了,如果把他存在堆中是没有什么意义的(还会浪费空间,后面说明)。可以这么说,基本类型和对象的引用都是存放在栈中,而且都是几个字节的一个数,因此在程序运行时,他们的处理方式是统一的。但是基本类型、对象引用和对象本身就有所区别了,因为一个是栈中的数据一个是堆中的数据。最常见的一个问题就是,Java 中参数传递时的问题。
¶Linux 进程堆管理
Linux 系统下,通过两个系统调用提供对堆空间进行分配:brk() 系统调用 和 mmap() 系统调用,这两种方式分配的都是虚拟内存,没有分配物理内存,在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系
在标准 C 库中,提供了 malloc/free 函数分配释放内存,这两个函数底层是由 brk,mmap,munmap 这些系统调用实现的
¶brk()系统调用
C 语言形式声明:
1 | int brk() {void* end_data_segment;} |
brk() 的作用是设置进程数据段的结束地址,即它可以扩大或者缩小数据段(Linux 下数据段和 BBS 合并在一起统称数据段),如果将数据段的结束地址向高地址移动,那么扩大的那部分空间就可以被程序使用,把这块空间拿过来使用作为堆空间是最常见的做法
¶mmap()系统调用
和 Windows 系统下的 VirtualAlloc 相似,mmap() 的作用就是向操作系统申请一段虚拟地址空间,(堆和栈中间,称为文件映射区域的地方)这块虚拟地址空间可以映射到某个文件。
glibc 的 malloc 函数是这样处理用户的空间请求的:对于小于 128KB 的请求来说,它会在现有的堆空间里面,按照堆分配算法为它分配一块空间并返回;对于大于 128KB 的请求来说,它会使用 mmap() 函数为它分配一块匿名空间,然后在这个匿名空间中为用户分配空间。
下面就是 mmap() 系统调用原型:
1 | void* mmap ( void* start ; size_t length ; int prot ; int flags ; int fd ; off_t offset ;) |
mmap 前两个参数分别用于指定需要申请的空间的起始地址和长度,如果起始地址设置 0,那么 Linux 系统会自动挑选合适的起始地址。prot/flags 参数:用于设置申请的空间的权限(可读,可写,可执行)以及映射类型(文件映射,匿名空间等)。最后两个参数用于文件映射时指定的文件描述符和文件偏移的
¶堆分配算法
本文简单介绍在 Linux 中的堆分配算法
¶空闲链表法
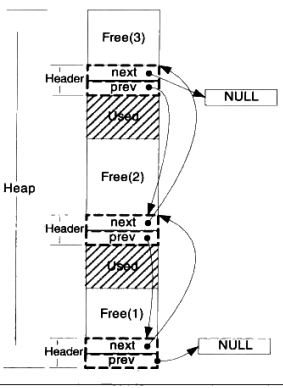
¶位图法
针对空闲链表的弊端,另一种分配方式显得更加稳健,这种方式称为位图(Bitmap)。
¶对象池
¶总结
¶附录
进程的内存结构(以 Java 为例)
浅谈程序的内存布局
进程结构和内存布局
为什么要把堆和栈区分出来呢?
为什么要有堆区和栈区呢?
为什么要有堆内存和栈内存之分?
内存为什么要分堆栈在编程里,要是全部只用堆或者全部只用栈,可行吗?