数据库物理建模
目录
¶关系型数据库设计规则
- 关系型数据库的典型数据结构就是数据表,这些数据表的组成都是结构化的(Structured)。
- 将数据放到表中,表再放到库中。
- 一个数据库中可以有多个表,每个表都有一个名字,用来标识自己。表名具有唯一性。
- 表具有一些特性,这些特性定义了数据在表中如何存储,类似 Java 和 Python 中 「 类 」的设计
¶表、记录、字段
E-R(entity-relationship,实体-联系)模型中有三个主要概念是:实体集、属性、联系集
| ER 图概念 | 数据库中概念 |
|---|---|
| 实体集 | 一个实体集对应于数据库中的一个表 |
| 实体 | 一个实体(instance)对应于数据库表中的一行(row),也称为一条记录(record) |
| 属性 | 一个属性对应于数据库表中的一列(column),也称为一个字段(field) |
¶ORM 思想 (Object Relational Mapping)
| 数据库 | 面向对象 |
|---|---|
| 数据库中的一个表 | 面向对象语言中的一个类 |
| 表中的一条数据 | 类实例化的一个对象 |
| 表中的一列 | 类中的一个字段、属性 |
¶表的关联关系
表与表之间的数据记录有关系(relationship)。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。目前存在四种关联关系:一对一关联、一对多关联、多对多关联以及自我引用
¶一对一关联(one-to-one)
在实际的开发中应用并不多,因为一对一可以创建到一张表中,没有必要创建两张表
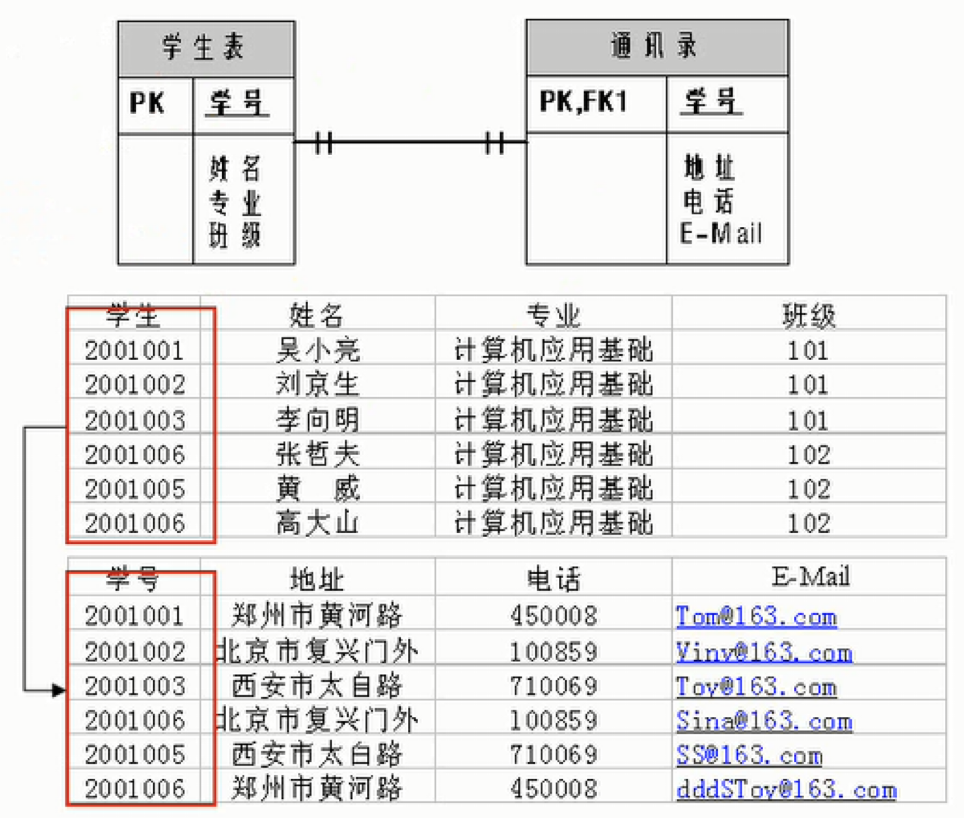
¶一对多关系(one-to-many)
常用实际场景:客户表和订单表、分类表和商品表以及部门表和员工表,一对多健表原则:在从表(多方)创建一个字段,字段作为外健指向主表(一方)的主键
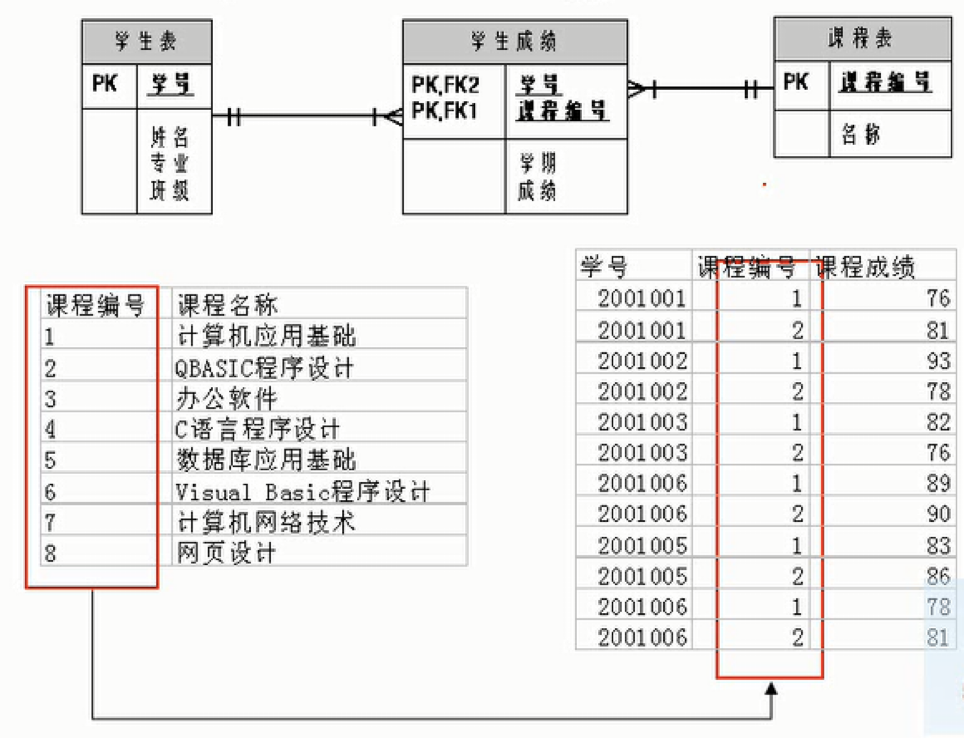
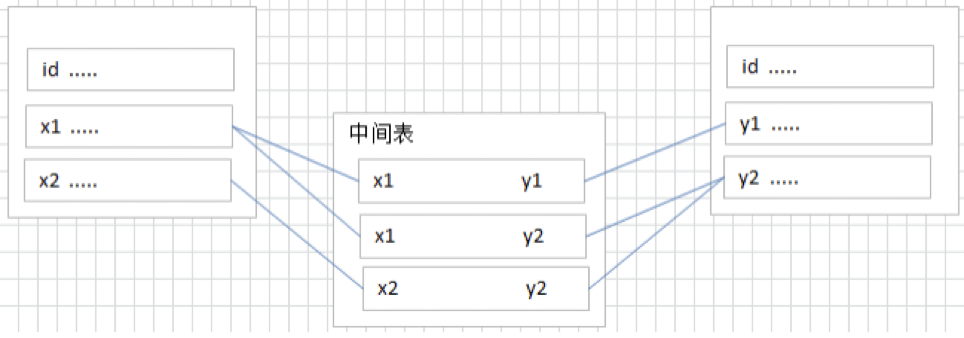
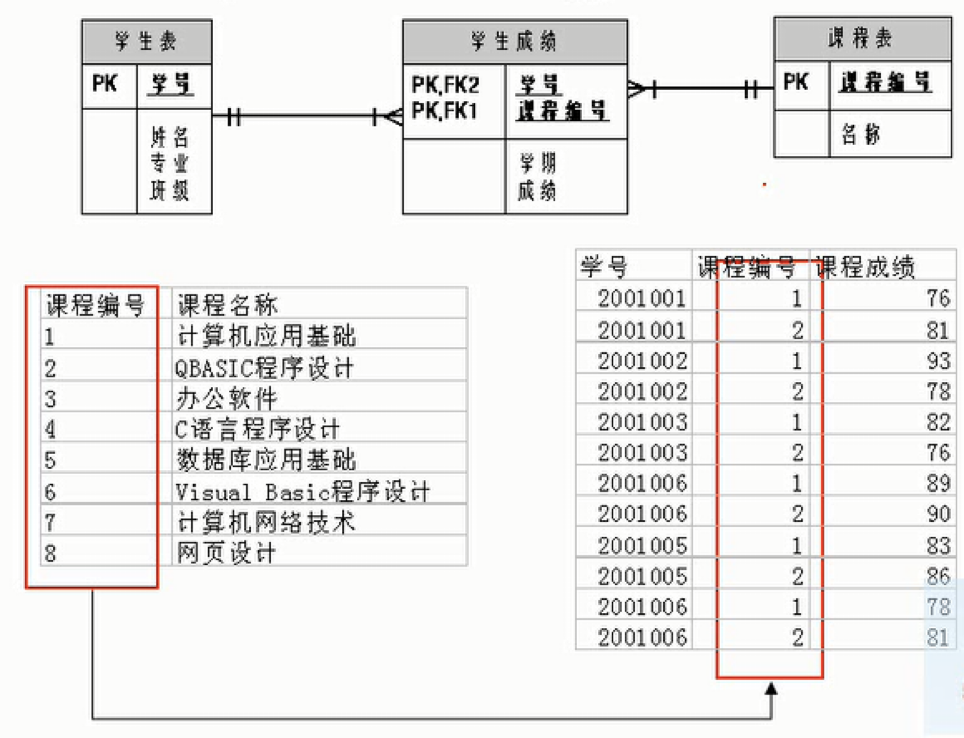
¶多对多关系(many-to-many)
要表示多对多关系必须创建第三个表,该表通常称为联接表,它将多对多关系划分为两个一对多关系,将这两个表的主键都插入到第三个表中
¶自我引用(self reference)
¶物理建模
✨物理建模就是主要包括两部分内容:确定最基本的表结构,以及对约束建模
¶理论
本小节主要记录数据库建模时需要使用的范数理论
¶第一范式

上面这个表中部门岗位应该拆分成两个字段:部门名称、岗位
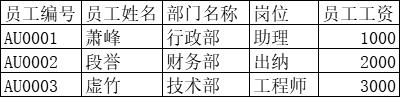
¶第二范式
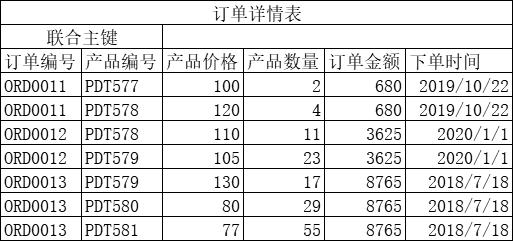
订单详情表 使用订单编号 和产品编号作为联合主键
此时产品价格、产品数量都和联合主键整体相关,但订单金额 和下单时间只和联合主键中的订单编号 相关, 和“产品编号” 无关。 所以只关联了主键中的部分字段, 不满足第二范式。
把“订单金额” 和“下单时间” 移到订单表就符合第二范式了
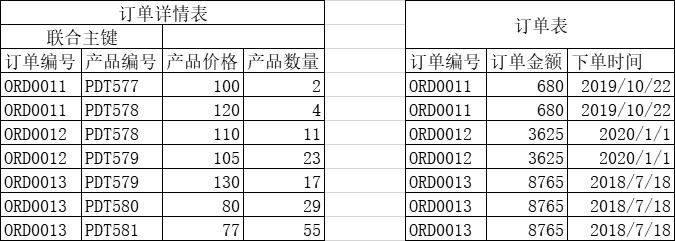
¶第三范式
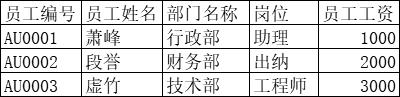
🐛上面表中的“部门名称” 和“员工编号” 的关系是“员工编号” →“部门编号”→“部门名称”, 不是直接相关,此时会带来下列问题 :
- 数据冗余:部门名称多次重复出现
- 插入异常:组件一个新部门时没有员工信息,也就无法单独插入部门信息。就算强行插入部门信息,员工表中没有员工信息的记录同样是非法记录
- 删除异常:删除员工信息会连带删除部门信息导致部门信息意外丢失
- 更新异常:哪怕只修改一个部门的名称也要更新多条员工记录
💡正确的做法是:把上表拆分成两张表,以外键形式关联

¶实践
❓项目中如何进行数据库建模
- 明白规则的变通:三大范式是设计数据库表结构的规则约束,但是在实际开发中允许局部变通
- 根据业务功能设计数据库表
- 看得见的字段(能够从需求文档或原型页面上直接看到的数据都需要设计对应的数据库表、字段来存储)
- 看不见的字段(保存一些相关数据)
- 冗余字段(为了避免建表时考虑不周有所遗漏,到后期再修改表结构非常麻烦,所以也有的团队会设置一些额外的冗余字段备用)
- 实际开发对接(实际开发中除了一些各个模块都需要使用的公共表再项目启动时创建好,其他专属于各个模块的表由该模块的负责人创建。但通常开发人员不能直接操作数据库服务器,所以需要把建表的 SQL 语句发送给运维工程师执行创建操作)
¶建模工具
对于数据模型的建模,最有名的要数 PowerDesigner,但是了解到国人开发的 pdMan 也挺好用的【研一暑假做项目时使用过,对于当时还是新手的我还是挺友好的】。其中 PowerDesigner 是一个很方便的建模工具,只需要拉个图形然后自动生成 sql 语句,它的优势在于:不用再使用 create table 等语句创建表结构,数据库设计人员只关注如何进行数据建模即可,将来的数据库语句,可以自动生成