垃圾回收算法
目录
¶概述
JVM 在进行垃圾回收时,主要分为两个阶段(标记阶段和清除阶段)进行,其中标记阶段用于搜集 JVM 中哪些对象需要进行回收,清除阶段用于对标记阶段的对象进行真正的回收,本文主要讲解这两个阶段所涉及的相关算法
¶标记阶段
在堆里存放着几乎所有的 Java 对象实例,在 GC 执行垃圾回收之前,首先需要区分出内存中哪些是存活对象,哪些是已经死亡的对象,只有被标记为己经死亡的对象,GC 才会在执行垃圾回收时,释放掉其所占用的内存空间,这个过程称为垃圾标记阶段
🤔JVM 究竟如何标记一个死亡对象?
¶引用计数算法
引用计数算法(Reference Counting)就是对每个对象保存一个整型的引用计数器属性,用于记录对象被引用的情况。对于一个对象 A,只要有任何一个对象引用了 A,则 A 的引用计数器就加 1;当引用失效时,引用计数器就减 1。只要对象 A 的引用计数器的值为 0,即表示对象 A 不可能再被使用,可进行回收
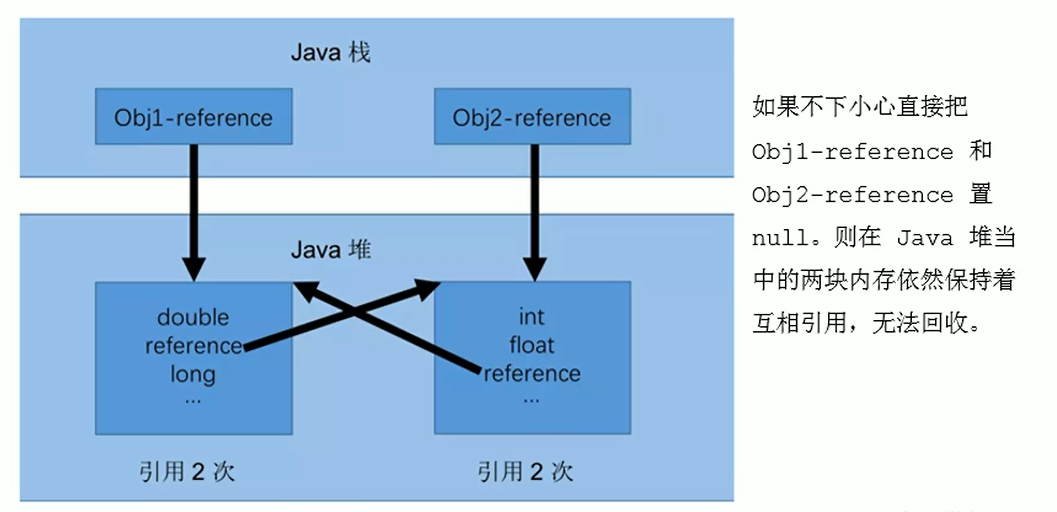
¶循环引用
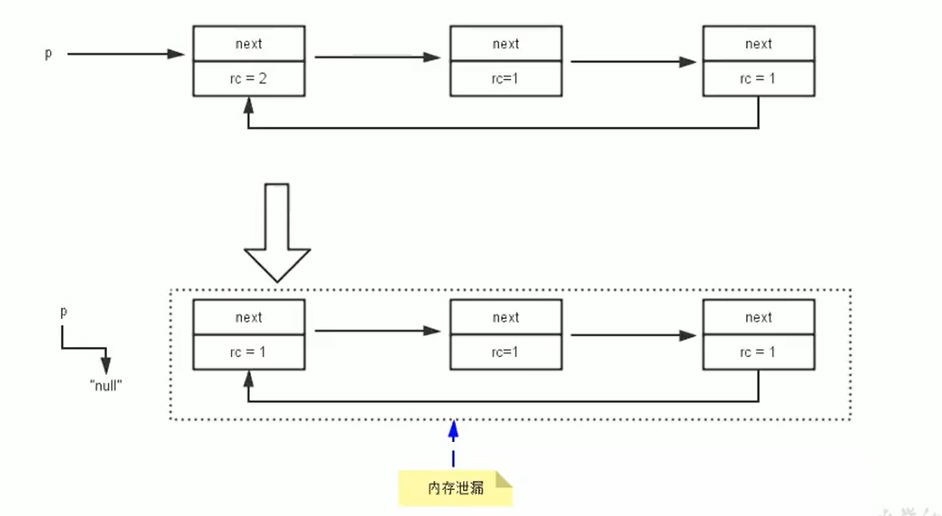
当p的指针断开的时候,内部引用形成循环,造成引用一直存在,循环引用必然导致内存泄漏
¶验证 Java 是否采用循环引用
1 | public class RefCountGC { |
上述进行了 GC 收集的行为,所以可以证明 JVM 中采用的不是引用计数器的算法
¶可达性分析算法
Java、C#使用的就是可达性分析算法来标记对象是否存活,这种类型的垃圾收集通常也叫作追踪性垃圾收集(Tracing Garbage Collection)
¶基本思路
❓可达性分析算法,是谁与谁可达?
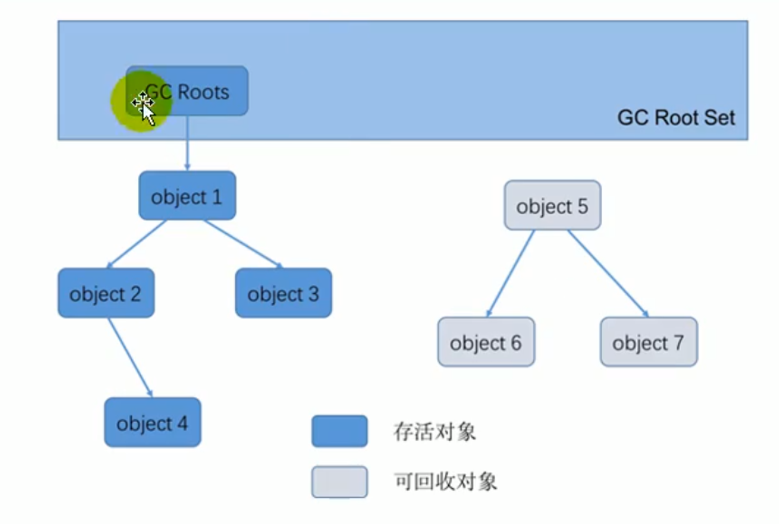
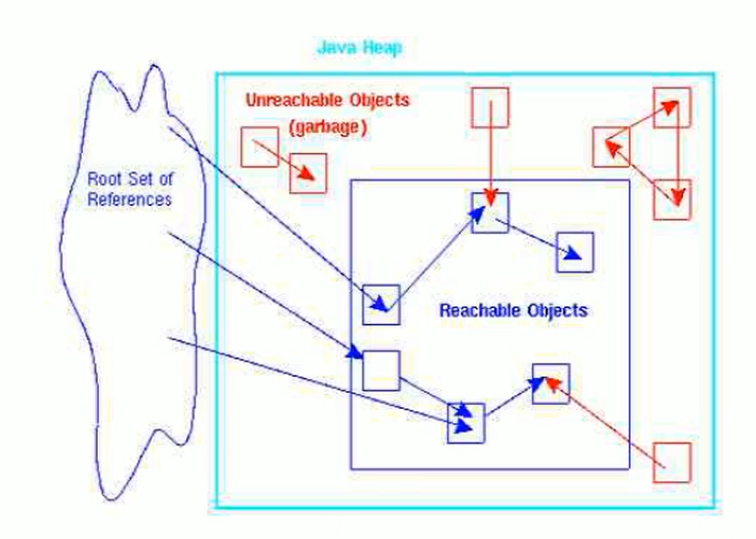
¶GC Roots
❓GCRoots 是什么?
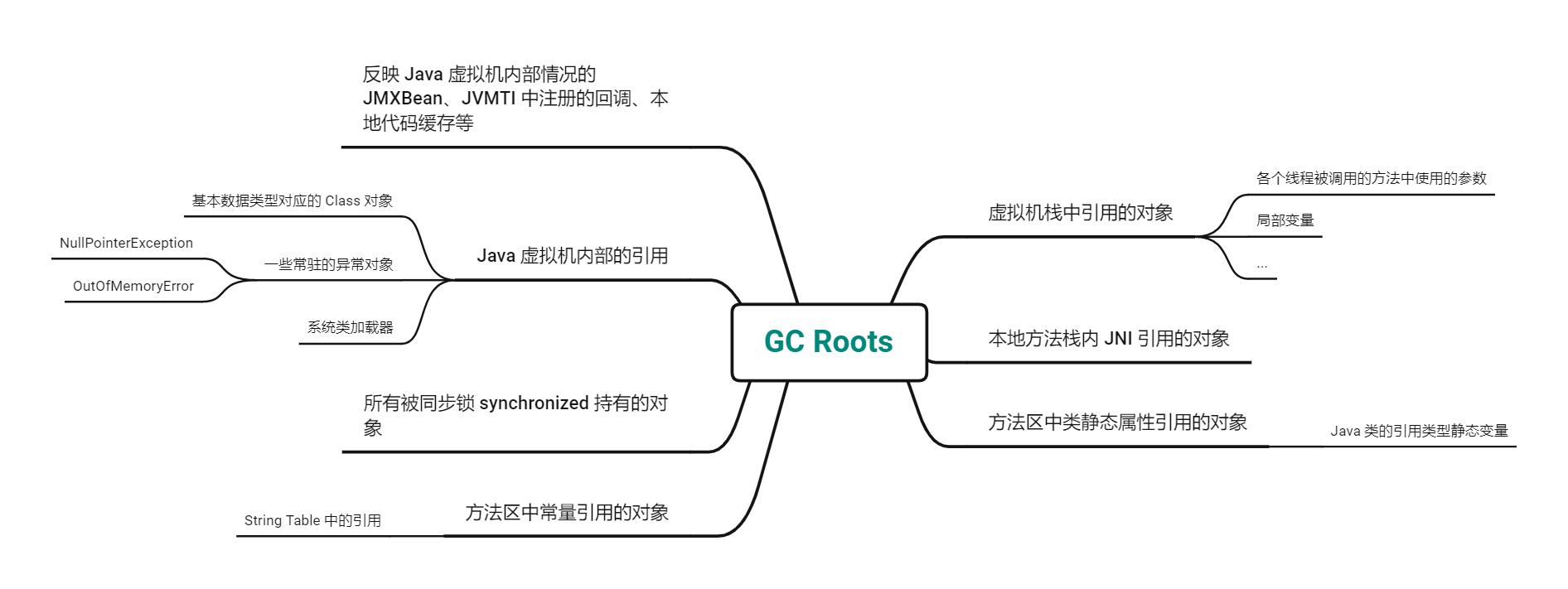
除了这些固定的 GC Roots 集合以外,根据用户所选用的垃圾收集器以及当前回收的内存区域不同,还可以有其他对象临时性地加入,共同构成完整 GC Roots 集合。比如:分代收集和局部回收(PartialGC)
如果只针对 Java 堆中的某一块区域进行垃圾回收(比如:典型的只针对新生代),考虑到内存区域是虚拟机自己的实现细节,更不是孤立封闭的,这个区域的对象完全有可能被其他区域的对象所引用,这时候就需要一并将关联的区域对象也加入GC Roots Set中去考虑,才能保证可达性分析的准确性
由于 Root 采用栈方式存放变量和指针,所以如果一个指针,它保存了堆内存里面的对象,但是自己又不存放在堆内存里面,那它就是一个 Root
¶总结
很多语言选择使用引用计数算法进行资源回收,Python 就使用引用计数算法标记对象,Java 并没有选择引用计数算法,因为很难处理循环引用关系,如此并不能说明引用计数算法不好,具体要看应用场景,业界中仍有大规模保留引用计数机制以提高吞吐量的尝试
🤔Python 是如何解决循环引用?
- 手动解除:在合适的时机,解除引用关系
- 使用弱引用
weakred,weakref是 python 提供的标准库,旨在解决循环引用
¶清除阶段
当成功区分出内存中存活对象和死亡对象后,GC 接下来的任务就是执行垃圾回收,释放掉无用对象所占用的内存空间,以便有足够的可用内存空间为新对象分配内存
¶标记清除算法
标记-清除算法(Mark-Sweep)是一种非常基础和常见的垃圾收集算法,该算法被J.McCarthy等人在 1960 年提出并,并应用于 Lisp 语言
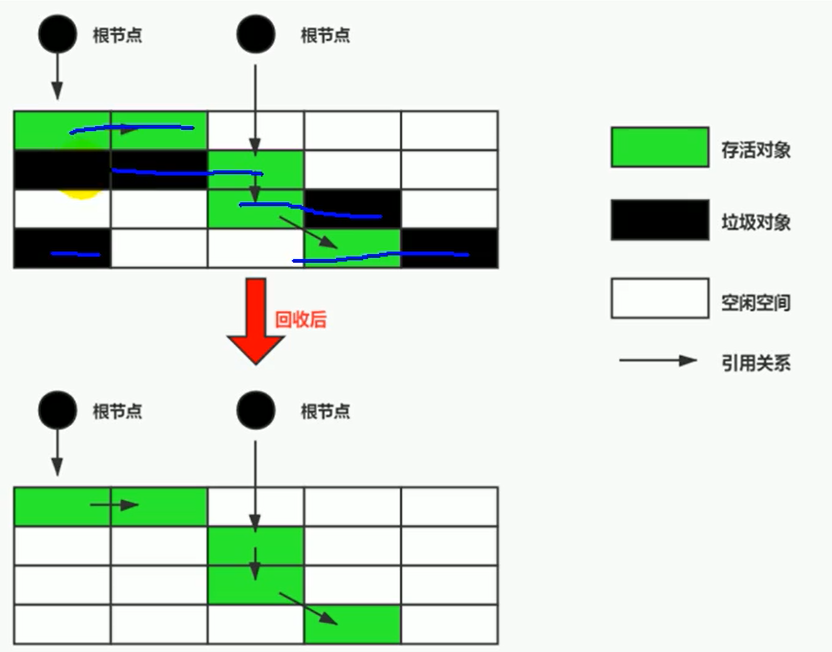
¶执行过程
当堆中的有效内存空间(available memory)被耗尽的时候,就会停止整个程序(STW),然后进行两项工作,第一项是标记,第二项是清除
¶清除的实现
这里所谓的清除并不是真的置空,而是把需要清除的对象地址保存在空闲的地址列表里。下次有新对象需要加载时,判断垃圾的位置空间是否够,如果够,就存放覆盖原有的地址。
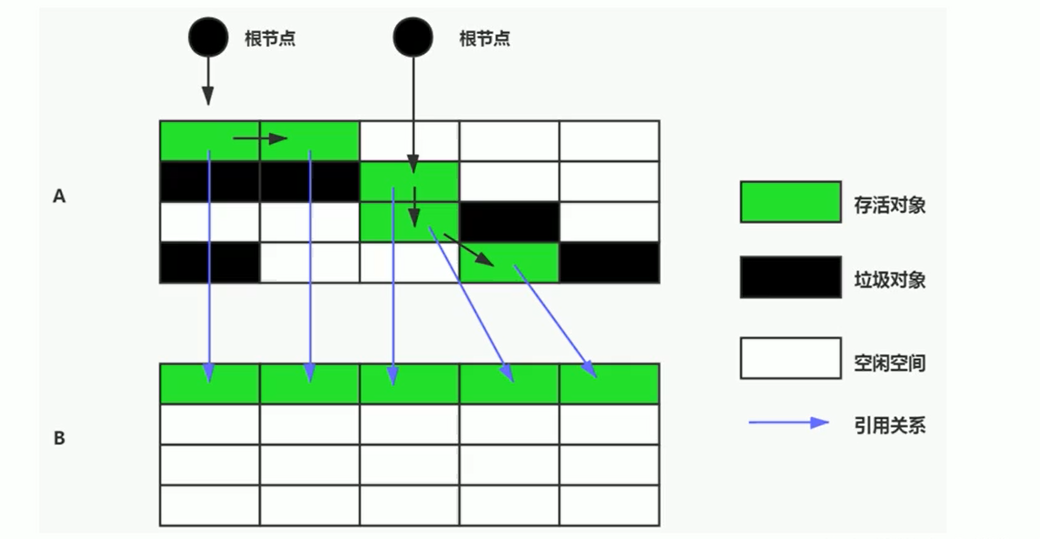
¶复制算法
为了解决标记-清除算法在垃圾收集效率方面的缺陷,提出了复制算法
复制算法需要复制的存活对象数量非常低才行,如果系统中存在很多的垃圾对象,不适合使用复制算法
¶核心思想
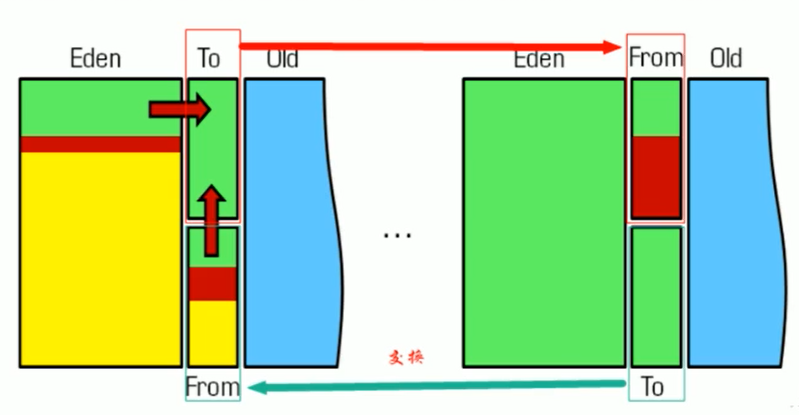
¶应用场景
为了解决空间利用率问题,可以将内存分为三块: Eden、From Survivor、To Survivor,比例是 8:1:1(大量测试后得到的一个结果),每次使用 Eden 和其中一块 Survivor。回收时,将 Eden 和 Survivor 中还存活的对象一次性复制到另外一块 Survivor 空间上,最后清理掉 Eden 和刚才使用的 Survivor 空间。这样只有 10% 的内存被浪费,但是我们无法保证每次回收都只有不多于 10% 的对象存活,当 Survivor 空间不够,需要依赖其他内存(指老年代)进行分配担保
✨分配担保
在新生代,对常规应用的垃圾回收,一次通常可以回收 70% - 99% 的内存空间,回收性价比很高,所以现代的商用虚拟机都是用这种收集算法回收新生代
¶标记压缩(整理)算法
复制算法的高效性是建立在存活对象少、垃圾对象多的前提下的。这种情况在新生代经常发生,但是在老年代,更常见的情况是大部分对象都是存活对象。如果依然使用复制算法,由于存活对象较多,复制的成本也将很高。因此,基于老年代垃圾回收的特性,需要使用其他的算法。
标记一清除算法的确可以应用在老年代中,但是该算法不仅执行效率低下,而且在执行完内存回收后还会产生内存碎片,所以 JVM 的设计者需要在此基础之上进行改进。标记-压缩(Mark-Compact)算法由此诞生
¶执行过程

标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,当我们需要给新对象分配内存时,JVM 只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销
🆚与标记清除算法相比,标记-清除算法是一种非移动式的回收算法,标记-压缩是移动式的,是否移动回收后的存活对象是一项优缺点并存的风险决策。
¶总结
标记-压缩算法的最终效果等同于标记-清除算法执行完成后,再进行一次内存碎片整理,因此,也可以把它称为标记-清除-压缩(Mark-Sweep-Compact)算法
¶清除阶段算法总结
| Mark-Sweep | Mark-Compact | Copying | |
|---|---|---|---|
| 速率 | 中等 | 最慢 | 最快 |
| 空间开销 | 少(但会堆积碎片) | 少(不堆积碎片) | 通常需要活对象的 2 倍空间(不堆积碎片) |
| 移动对象 | 否 | 是 | 是 |
¶分代收集算法
前面所有这些算法中,并没有一种算法可以完全替代其他算法,它们都具有自己独特的优势和特点。
目前几乎所有的 GC 都采用分代收集算法执行垃圾回收的,在 HotSpot 中,基于分代的概念,GC 所使用的内存回收算法结合年轻代和老年代各自的特点
¶年轻代(Young Gen)
¶老年代(Tenured Gen)
📓各个阶段开销总结
Mark 阶段的开销与存活对象的数量成正比。
Sweep 阶段的开销与所管理区域的大小成正相关。
Compact 阶段的开销与存活对象的数据成正比。
以 HotSpot 中的 CMS 回收器为例,CMS 是基于 Mark-Sweep 实现的,对于对象的回收效率很高。而对于碎片问题,CMS 采用基于 Mark-Compact 算法的 Serial Old 回收器作为补偿措施:当内存回收不佳(碎片导致的 Concurrent Mode Failure 时),将采用 Serial Old 执行 Full GC 以达到对老年代内存的整理
分待的思想被现有的虚拟机广泛使用,几乎所有的垃圾回收器都区分成新生代和老年代
¶增量收集算法
上述现有的算法,在垃圾回收过程中,应用软件将处于一种Stop the World的状态。在 Stop the World 状态下,应用程序所有的线程都会挂起,暂停一切正常的工作,等待垃圾回收的完成。如果垃圾回收时间过长,应用程序会被挂起很久,将严重影响用户体验或者系统的稳定性。为了解决这个问题,即对实时垃圾收集算法的研究直接导致了增量收集(Incremental Collecting)算法的诞生
增量算法的基本思想如下:
总的来说,增量收集算法的基础仍是传统的标记-清除和复制算法。增量收集算法通过对线程间冲突的妥善处理,允许垃圾收集线程以分阶段的方式完成标记、清理或复制工作
¶分区算法
¶总结
以上介绍的都只是基本的算法思路,实际 GC 实现过程要复杂的多,目前还在发展中的前沿 GC 都是复合算法,并且并行和并发兼备