分布式 ID 生成系统解决方案
目录
¶概述
❓什么是全局分布式 ID?
❓为什么需要用全局分布式 ID?
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求;如订单、骑手、优惠券也都需要有唯一 ID 做标识。
❓全局分布式 ID 要完成哪些功能?
📓一个 ID 生成系统应该做到以下几点:平均延迟和 TP999 延迟都要尽可能低;可用性 5 个 9;高 QPS
¶分布式 ID 生成方式
✨常见的存在以下九种分布式 ID 生成方式:

¶UUID
UUID(Universally Unique Identifier)的标准型式包含 32 个 16 进制数字,以连字号分为五段,形式为8-4-4-4-12的 36 个字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前为止业界一共有 5 种方式生成 UUID,详情见 IETF 发布的 UUID 规范A Universally Unique IDentifier (UUID) URN Namespace
1 | public static void main(String[] args) { |
🆚优缺点分析
All indexes other than the clustered index are known as secondary indexes. In InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index. InnoDB uses this primary key value to search for the row in the clustered index.If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key
📓UUID 的生成非常简单,但是并不适用于实际的业务需求。用作订单号这样的字符串没有丝毫的意义,看不出和订单相关的有用信息;对于数据库查询也非常不利,并不是非常推荐使用 UUID 作为分布式 ID 生成器
¶基于数据库自增 ID
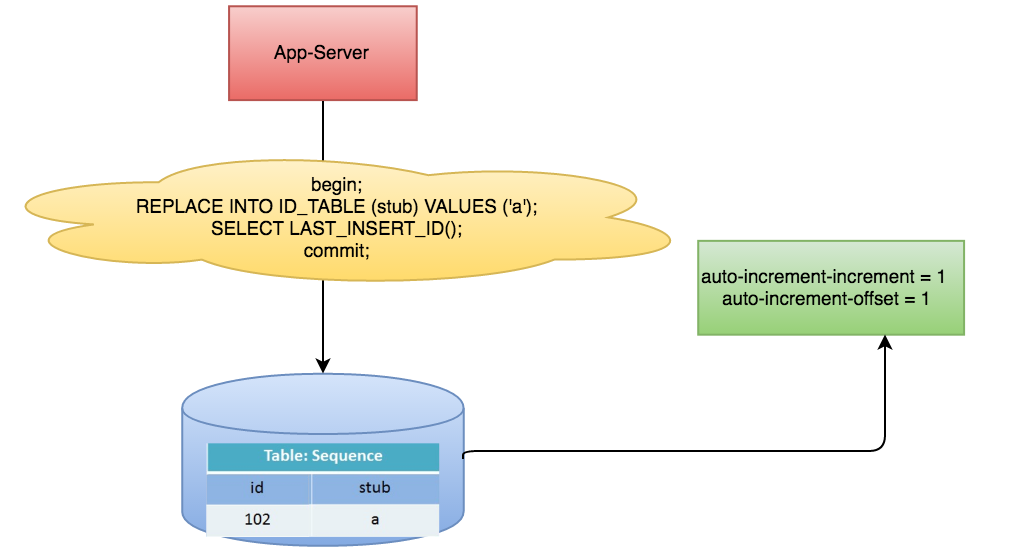
基于数据库的auto_increment自增 ID 完全可以充当分布式 ID。具体实现:需要一个单独的 MySQL 实例用来生成 ID,建表结构如下:
1 | CREATE DATABASE `SEQ_ID`; |
🆚优缺点分析
📓当我们需要一个 ID 的时候,向表中插入一条记录返回主键 ID,但这种方式有一个比较致命的缺点,访问量激增时 MySQL 本身就是系统的瓶颈,用它来实现分布式服务风险比较大,不推荐!
¶基于数据库集群模式
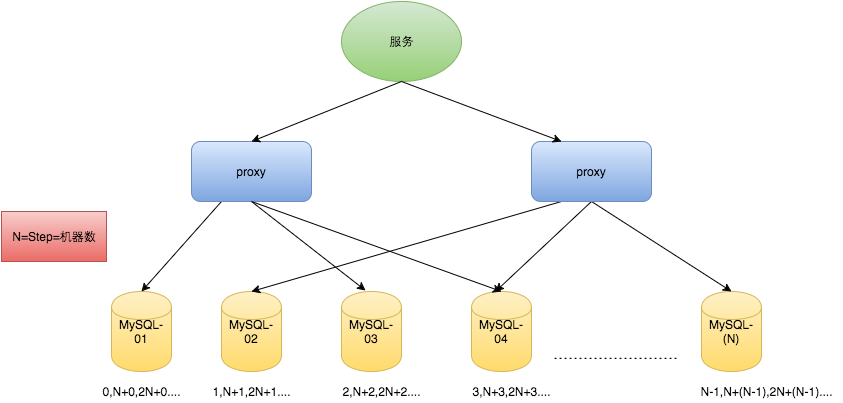
单点数据库方式不可取,对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个 Mysql 实例都能单独的生产自增 ID。那这样还会有个问题,两个 MySQL 实例的自增 ID 都从 1 开始,会生成重复的 ID,可以使用如下方式解决:
1 | TicketServer1: |
假设我们要部署 N 台机器,步长需设置为 N,每台的初始值依次为 0,1,2…N-1 那么整个架构就变成了如下图所示:
❓如果集群后的性能还是扛不住高并发咋办?
🆚优缺点分析
¶基于数据库的号段模式
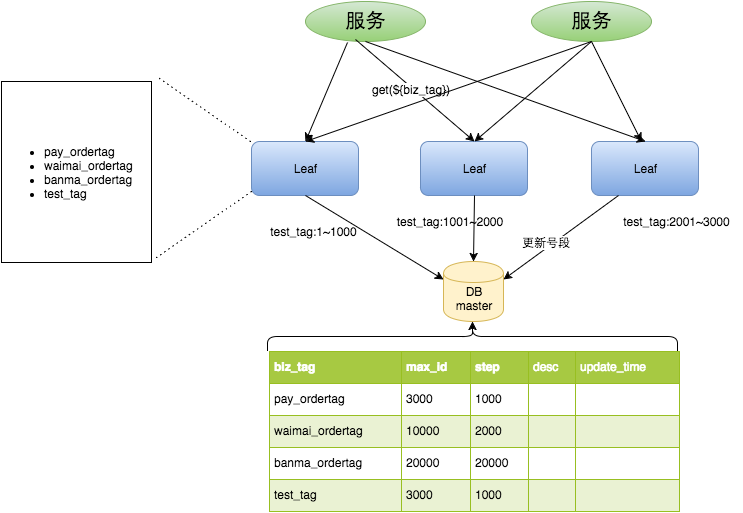
号段模式是当下分布式 ID 生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增 ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表 1000 个 ID,具体的业务服务将本号段,生成 1~1000 的自增 ID 并加载到内存。表结构如下:
1 | CREATE TABLE id_generator ( |
| 字段 | 含义 |
|---|---|
| biz_type | 代表不同业务类型 |
| max_id | 当前最大的可用 id |
| step | 代表号段的长度 |
| version | 是一个乐观锁,每次都更新 version,保证并发时数据的正确性 |
例如:生成的 ID 在数据库表中存储为如下信息:
| id | biz_type | max_id | step | version |
|---|---|---|---|---|
| 1 | 101 | 1000 | 2000 | 0 |
等这批号段 ID 用完,再次向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update 成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]、
1 | update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX |
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多
¶基于 Redis 模式
Redis也同样可以实现,原理就是利用redis的 incr命令实现 ID 的原子性自增
1 | 127.0.0.1:6379> set seq_id 1 // 初始化自增ID为1 |
✨用redis实现需要注意一点,要考虑到 redis 持久化的问题。redis有两种持久化方式RDB和AOF
¶雪花算法

雪花算法(Snowflake)是 twitter 公司内部分布式项目采用的 ID 生成算法,最终生成的是占 8 个字节 Long 类型的 ID
¶百度(uid-generator)
uid-generator是基于Snowflake算法实现的,与原始的 snowflake 算法不同在于,uid-generator 支持自定义时间戳、工作机器 ID和序列号等各部分的位数,而且uid-generator中采用用户自定义workId的生成策略
¶美团(Leaf)
Leaf同时支持号段模式和snowflake算法模式,可以切换使用
¶号段模式
1 | DROP TABLE IF EXISTS `leaf_alloc`; |
然后在项目中开启号段模式,配置对应的数据库信息,并关闭snowflake模式,字段模式大致架构如下:
¶snowflake 模式
Leaf的 snowflake 模式依赖于ZooKeeper,与原始 snowflake 算法在workId的生成上不同。Leaf中workId是基于ZooKeeper的顺序 Id 来生成的,每个应用在使用Leaf-snowflake时,启动时都会都在Zookeeper中生成一个顺序 Id,相当于一台机器对应一个顺序节点,也就是一个workId
¶滴滴(Tinyid)
Tinyid是基于号段模式原理实现的与Leaf如出一辙,这里不给出详细使用方式