缓冲区
目录
¶概述
缓冲区是一个用于存储特定数据类型的容器,由 java.nio 包定义,目前常用的缓冲区都是 Buffer 抽象类的子类。Java NIO 中的 Buffer 主要用于与 NIO 通道进行交互。在 NIO 中,如果用户想要消费数据,数据首先会从通道读入缓冲区,随后用户在缓冲区中消费数据。对应地,用户如果想要排出数据,数据首先会从缓冲区写入通道中,随后通过通道排出数据。具体的示意图如下:
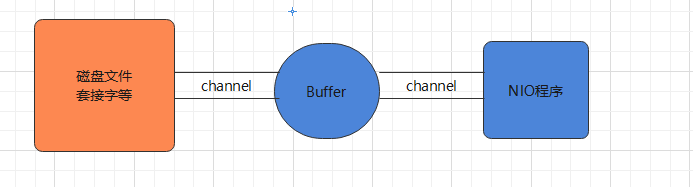
¶Buffer 类及其子类
Buffer 就像一个数组,可以保存多个相同类型的数据。根据数据类型不同,有以下常用子类:
| ByteBuffer | CharBuffer | CharBuffer | CharBuffer | LongBuffer | LongBuffer | LongBuffer |
上述 Buffer 类他们都采用相似的方法进行管理数据,只是各自管理的数据类型不同而已。都是通过如下方法获取一个 Buffer 对象:
1 | //创建一个容量为 capacity 的 XxxBuffer 对象 |
¶缓冲区的基本属性
一个缓冲区具有如下四个最重要的基本属性(mark、position、limit、capacity),它们遵守以下不等式:0 <= mark <= position <= limit <= capacity
| 基本属性 | 含义 |
|---|---|
| 容量 (capacity) | 作为一个内存块,Buffer具有一定的固定大小,也称为"容量",缓冲区容量不能为负,并且创建后不能更改 |
| 限制 (limit) | 表示缓冲区中可以操作数据的大小(limit 后数据不能进行读写)。缓冲区的限制不能为负,并且不能大于其容量 写入模式,限制等于buffer的容量 读取模式下,limit等于写入的数据量 |
| 位置(position) | 下一个要读取或写入的数据的索引。缓冲区的位置不能为 负,并且不能大于其限制(limit) |
| 标记 (mark)与重置 (reset) | 标记是一个索引,通过 Buffer 中的 mark() 方法 指定 Buffer 中一个特定的 position,之后可以通过调用 reset() 方法恢复到这 个 position |
简单的相关操作如下:
¶缓冲区常用方法
| 常用API | 含义 |
|---|---|
| Buffer clear() | 清空缓冲区并返回对缓冲区的引用 |
| Buffer flip() | 将缓冲区的界限设置为当前位置,并将当前位置重置为 0,由写模式转换为读模式 |
| int capacity() | 返回 Buffer 的 capacity 大小 |
| boolean hasRemaining() | 判断缓冲区中是否还有元素 |
| int limit() | 返回 Buffer 的界限(limit) 的位置 |
| Buffer limit(int n) | 设置缓冲区界限为 n, 并返回一个具有新 limit 的缓冲区对象 |
| Buffer mark() | 对缓冲区设置标记 |
| int position() | 返回缓冲区的当前位置 position |
| Buffer position(int n) | 将设置缓冲区的当前位置为 n , 并返回修改后的 Buffer 对象 |
| int remaining() | 返回 position 和 limit 之间的元素个数 |
| Buffer reset() | 将位置 position 转到以前设置的 mark 所在的位置 |
| Buffer rewind() | 将位置设为为 0, 取消设置的 mark |
¶缓冲区的数据操作
Buffer 所有子类提供了两个数据操作的方法:get() & put()方法来获取及写入 Buffer中的数据
| 常用API | 含义 |
|---|---|
| get() | 读取单个字节 |
| get(byte[] dst) | 批量读取多个字节到 dst 中 |
| get(int index) | 读取指定索引位置的字节(不会移动 position) |
| put(byte b) | 将给定单个字节写入缓冲区的当前位置 |
| put(byte[] src) | 将 src 中的字节写入缓冲区的当前位置 |
| put(int index, byte b) | 将指定字节写入缓冲区的索引位置(不会移动 position) |
¶ByteBuffer使用案例
✨ 使用Buffer读写数据一般遵循以下四个步骤:
- 写入数据到Buffer
- 调用
flip()方法,转换为读模式 - 从Buffer中读取数据
- 调用
buffer.clear()方法或者buffer.compact()方法切换至写模式
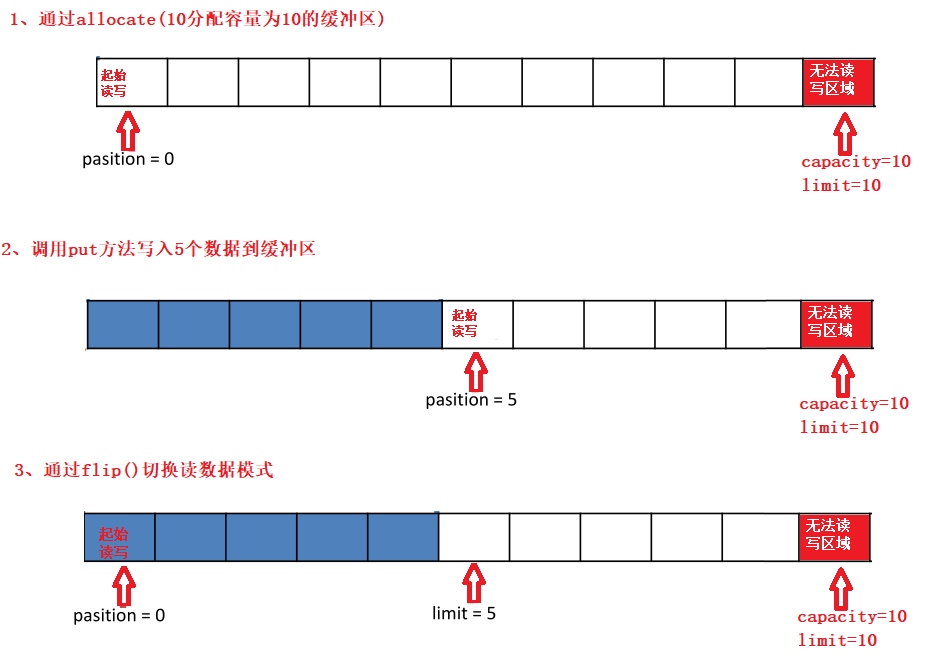
一开始情况下,整个ByteBuffer中比较重要的三个属性(position,limit,capacity)初始化如下:
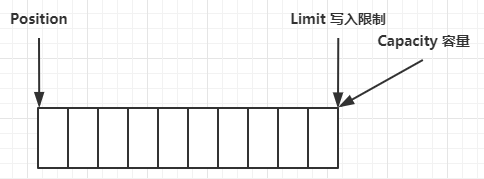
写模式下,position 是写入位置,limit 等于容量,下图表示写入了 4 个字节后的状态

flip 动作发生后,position 切换为读取位置,limit 切换为读取限制
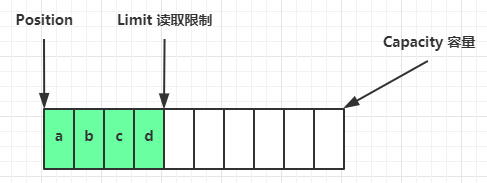
读取 4 个字节后,状态
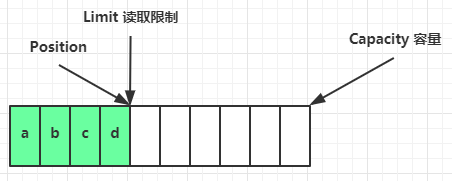
clear 动作发生后,状态
compact 方法,是把未读完的部分向前压缩,然后切换至写模式
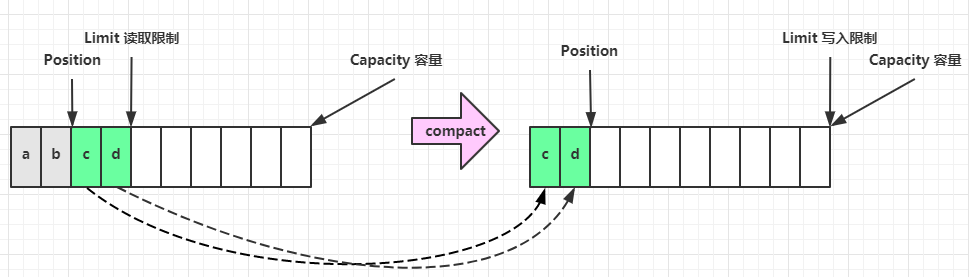
¶向 buffer 写入数据
存在两种方法向 buffer 中写入数据:
- 调用 channel 的 read 方法
1 | int readBytes = channel.read(buf); |
- 调用 buffer 自己的 put 方法
1 | buf.put((byte)127); |
¶从 buffer 中读取数据
同样存在两种方式从 buffer 中读取数据
- 调用 channel 的 write 方法
1 | int writeBytes = channel.write(buf); |
- 调用 buffer 自己的 get 方法
1 | byte b = buf.get(); |
get 方法会让 position 读指针向后走,如果想重复读取数据,有两种方法:
¶mark 和 reset
mark 是在读取时,做一个标记,即使 position 改变,只要调用 reset 就能回到 mark 的位置
📓 rewind 和 flip 都会清除 mark 位置
¶字符串与 ByteBuffer 互转
1 | //字符串转换为 bytebuffer |
¶直接与非直接缓冲区
byte byffer可以是两种类型,一种是基于直接内存(也就是非堆内存);另一种是非直接内存(也就是堆内存)。
🆚 直接缓冲区与非直接缓冲区
在做IO处理时,比如网络发送大量数据时,直接内存会具有更高的效率。直接内存使用 allocateDirect 创建,但是它比申请普通的堆内存需要耗费更高的性能。
不过,这部分的数据是在JVM之外的,因此它不会占用应用的内存。所以,当你有很大的数据要缓存,并且它的生命周期又很长,那么就比较适合使用直接内存。只是一般来说,如果不是能带来很明显的性能提升,还是推荐直接使用堆内存。
字节缓冲区是直接缓冲区还是非直接缓冲区可通过调用其 isDirect() 方法来确定。
✨ 使用场景
¶分散和汇聚
许多操作系统都能把组装/分解过程进行得更加高效。根据发散/汇聚的概念,进程只需一个系 统调用,就能把一连串缓冲区地址传递给操作系统。然后,内核就可以顺序填充或排干多个缓冲 区,读的时候就把数据发散到多个用户空间缓冲区,写的时候再从多个缓冲区把数据汇聚起来
这样用户进程就不必多次执行系统调用,内核也可以优化数据的处理过程,因为它已掌握待传输数据的全部信息。如果系统配有多个 CPU ,甚至可以同时填充或排干多个缓冲区。
¶Scattering reads
分散读取,这样就可以一次性将读取到的内容分散在多个不同的 buffer 中,减少了一个 buffer 重复读取的次数。
1 | try (RandomAccessFile file = new RandomAccessFile("helloword/3parts.txt", "rw")) { |
¶Gathering Writes
1 | try (RandomAccessFile file = new RandomAccessFile("helloword/3parts.txt", "rw")) { |