分布式事务概述
目录
¶概述
❓为什么会有分布式事务?

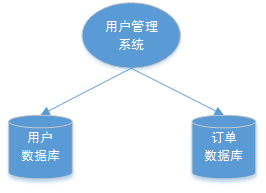
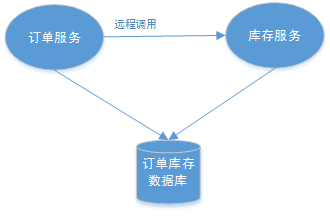
📓总结下来,存在三种场景会产生分布式事务
❓什么是分布式事务?
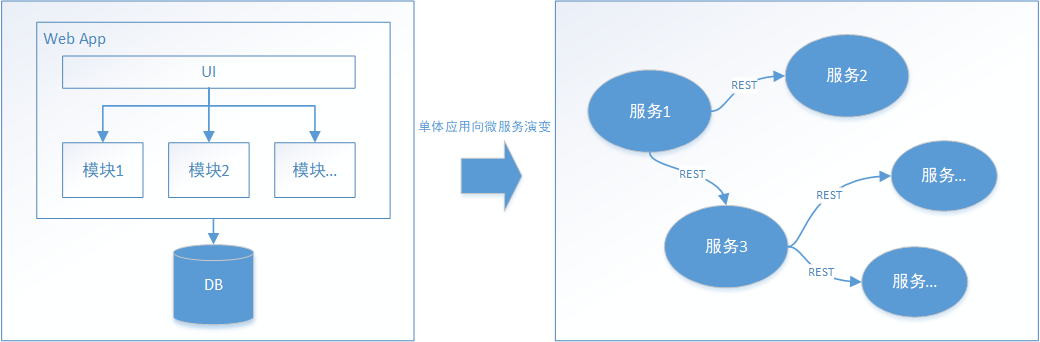
本地事务依赖于数据库本身提供的事务特性来实现,因此以下逻辑可以控制本地事务:
1 | begin transaction; |
在分布式环境下,事务操作会变成下边这样:
1 | begin transaction; |
📓分布式系统中,传统数据库事务无法使用,网络的不稳定性是导致分布式事务产生的根本原因
¶分布式事务基础理论
本小节总结分布式场景下系统的事务特点,与传统数据库事务的 ACID 不同,分布式系统存在 CAP 和 BASE 两种常见理论,通过这两种理论可以更加深入的理解分布式系统中的事务模型
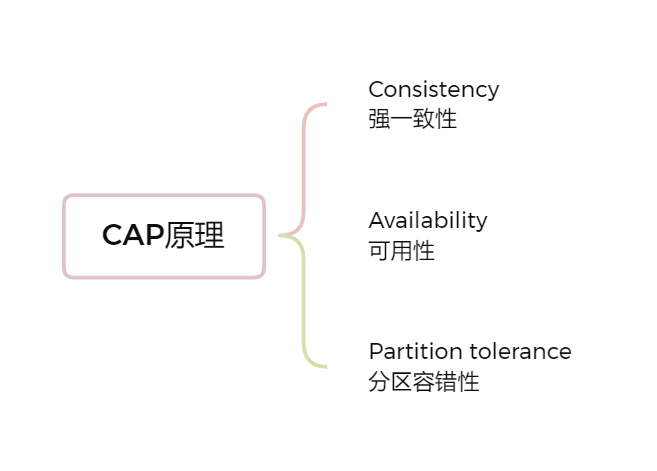
¶CAP 原理
CAP 是 Consistency、Availability、Partition tolerance三个词语的缩写,分别表示一致性、可用性、分区容忍性
¶应用场景
结合电商系统中的一些业务场景来理解 CAP,如下图,是商品信息管理的执行流程:
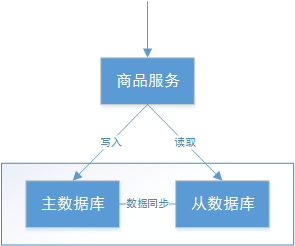
⛵整体执行流程如下:
- 商品服务请求主数据库写入商品信息(添加商品、修改商品、删除商品)
- 主数据库向商品服务响应写入成功
- 商品服务请求从数据库读取商品信息
¶一致性(Consistency)
上面那个例子,商品信息的读写要满足一致性就是要实现如下目标:
- 商品服务写入主数据库成功,则向从数据库查询新数据也成功
- 商品服务写入主数据库失败,则向从数据库查询新数据也失败
✨分布式系统一致性满足的特点
❓如何实现一致性?
- 写入主数据库后要将数据同步到从数据库
- 写入主数据库后,在向从数据库同步期间要将从数据库锁定,待同步完成后再释放锁,以免在新数据库写入成功后,向从数据库查询到旧的数据
¶可用性(Availability)
上面那个例子,商品信息读取满足可用性就是要实现如下目标:
- 从数据库接收到数据查询的请求则立即能够响应数据查询结果
- 从数据库不允许出现响应超时或响应错误
❓如何实现可用性?
- 写入主数据库后要将数据同步到从数据库
- 由于要保证从数据库的可用性,不可将从数据库中的资源进行锁定
- 即时数据还没有同步过来,从数据库也要返回要查询的数据,哪怕是旧数据,如果连旧数据也没有则可以按照约定返回一个默认信息,但不能返回错误或响应超时
✨分布式系统可用性的特点:所有请求都有响应,且不会出现响应超时或响应错误
¶分区容错性(Partition tolerance)
上面那个例子,商品信息读写满足分区容忍性就是要实现如下目标:
- 主数据库向从数据库同步数据失败,不影响从数据库的读写操作
- 一个结点挂掉不影响另一个结点对外提供服务
❓如何实现分区容忍性?
- 尽量使用异步取代同步操作,例如使用异步方式将数据从主数据库同步到从数据,这样结点之间能有效的实现松耦合
- 添加从数据库结点,其中一个从结点挂掉其它从结点提供服务
✨分布式系统分区容忍性的特点:分区容忍性时分布式系统具备的基本能力
¶CAP 组合方式
❓上面商品管理的例子是否同时具备 CAP 的特性尼?
商品管理的例子满足了分布容错性如图,本图中分区容错性的含义是:
📓通过以上分析可以确认,如果一个系统是在网络分区中,那么可用性和一致性是相互矛盾的,最终 CAP 理论可以使用下图描述
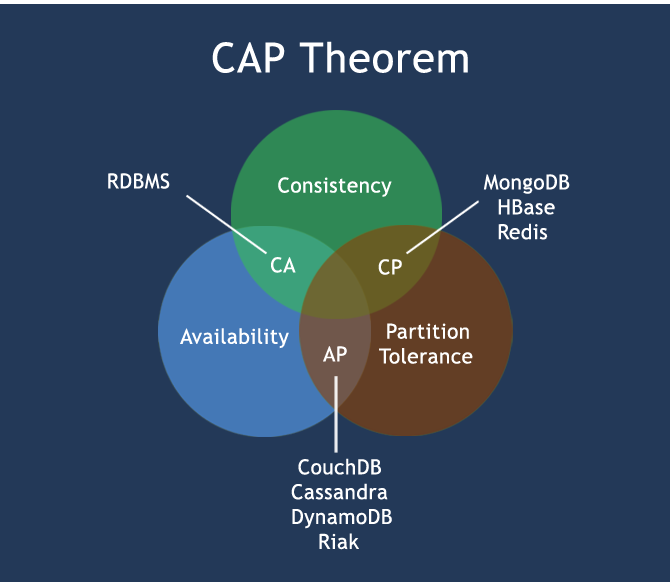
所以在生产中对分布式事务处理时要根据需求来确定满足 CAP 的哪两个方面,常见的 CAP 组合方式由以下三种:
¶总结
📓CAP 理论核心:一个分布式系统不可能同时很好的满足一致性、可用性和分区容错性这三个需求,最多只能同时较好的满足两个。尤其对于多数大型互联网应用的场景,结点众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到 N 个 9(99.99…%),并要达到良好的响应性能来提高用户体验,因此一般都会做出如下选择:保证 P 和 A ,舍弃 C (强一致),保证最终一致性
❓为什么只能满足两个?
而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是存储系统必须实现的,所以常常只能在一致性和可用性之间进行权衡,不存在任何一个系统能够同时保证这三点
✨一致性和可用性之间必须做出一个取舍,所幸当前大多数 Web 应用,其实并不需要强一致性,因此牺牲 C 换取 P,这是目前分布式数据库产品的方向
¶BASE 理论
CAP 理论告诉我们一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这三项中的两项,其中 AP 在实际应用中较多,AP 即舍弃一致性,保证可用性和分区容忍性,但是在实际生产中很多场景都要实现一致性,比如前边举的例子主数据库向从数据库同步数据。
¶一致性再探究
即使分布式系统损失一致性,但是最终也要将数据同步成功来保证数据一致,其实这种一致性和 CAP 中的一致性不同,CAP 中的一致性要求在任何时间查询每个结点数据都必须一致,它强调的是强一致性,但是最终一致性是允许可以在一段时间内每个结点的数据不一致,经过一段时间每个结点的数据必须一致,它强调的是最终数据的一致性
🆚强一致性和最终一致性的异同
📖其实除了以上说的强一致性和最终一致性外,还存在弱一致性
📓一致性总结
¶理论探究
❓什么是 BASE 理论
BASE 是 Basically Available(基本可用), Soft-state(软状态), Eventually consistent(最终一致性)的缩写,BASE 理论是对 CAP 中 AP 的一个扩展,通过牺牲强一致性来获得可用性,当出现故障允许部分不可用但要保证核心功能可用,允许数据在一段时间内是不一致的,但最终一致性,称之为柔性事务
❓什么是Basically Available(基本可用)
❓什么是Soft-state(软状态)
❓什么是Eventually consistent(最终一致性)
¶柔性事务
不同于 ACID 的刚性事务,在分布式场景下基于 BASE 理论,就出现了柔性事务的概念。要想通过柔性事务来达到最终的一致性,就需要依赖于一些特性,这些特性在具体的方案中不一定都要满足,因为不同的方案要求不一样;但是都不满足的话,是不可能做柔性事务的